Kubernetes
쿠버네티스 입문 Wiki
- 용어해설
- 쿠버네티스 개요
- 쿠버네티스 네트워킹
- 쿠버네티스 스토리지
- 쿠버네티스 RBAC
- 쿠버네티스 애플리케이션 배포
- Pod 템플릿 정의하기
- Deployment 리소스 소개
- ReplicaSet 리소스 소개
- StatefulSet 리소스 소개
- DaemonSet 리소스 소개
- HPA(Horizontal Pod Autoscaler) 리소스 소개
- Job & CronJob 리소스 소개
- 쿠버네티스 클러스터 관리
용어해설
| 용어 | 정의 |
|
쿠버네티스 (Kubernetes) |
컨테이너 오케스트레이션 도구로, 대규모 분산 시스템을 쉽게 관리할 수 있게 해주는 오픈소스 플랫폼 |
| K8s | 쿠버네티스(Kubernetes)의 약어로, 컨테이너 오케스트레이션 도구를 간단하게 부르는 방법 |
| 오브젝트 | 쿠버네티스에서 오브젝트는 쿠버네티스 시스템에서 관리하는 기본 단위 |
| 오픈소스 | 공개된 소프트웨어로, 소스 코드를 누구나 열람하고 수정할 수 있는 소프트웨어를 의미 |
| 컨테이너 | 소프트웨어를 격리된 환경에서 실행할 수 있도록 도와주는 기술로, 가상화 기술의 일종 |
| 컨테이너화 | 애플리케이션을 컨테이너에 담아서 실행 가능한 형태로 만드는 기술 |
| 배포 | 소프트웨어나 애플리케이션을 실제 사용 환경에 설치하고 실행할 수 있도록 전달하는 과정 |
| 스케일링 | 시스템이나 애플리케이션의 성능을 유연하게 조절하면서 대규모 트래픽 처리나 높은 가용성을 유지하기 위한 기술 |
|
Borg |
구글이 개발한 대규모 클러스터 관리 시스템으로, Kubernetes의 전신이 되는 기술 |
| 모놀리식 (monolithic) | 전통적인 방식의 소프트웨어 아키텍처로, 모든 기능을 하나의 애플리케이션으로 구성하는 방식 |
| LAMP 스택 | 리눅스, 아파치, MySQL, PHP를 조합한 오픈소스 웹 개발 환경을 의미 |
| Docker | 컨테이너 기반 가상화 플랫폼으로, 애플리케이션을 컨테이너로 추상화하여 배포 및 관리를 용이하게 해주는 기술 |
| Podman | 컨테이너 기반 가상화 플랫폼으로, Docker와 유사한 기능을 제공하지만 데몬 없이 컨테이너를 관리할 수 있는 기술 |
| LXC | 리눅스 컨테이너를 만들고 관리하기 위한 운영 체제 레벨 가상화 기술 |
| 마이크로서비스 | 작고 독립적인 기능을 갖는 애플리케이션으로, 각각이 분리되어 개발, 배포, 확장이 가능한 아키텍처 패턴 |
| 오케스트레이션 | 서로 다른 요소를 결합하여 큰 작업을 수행한다는 과정 (예: 지휘자가 음악 공연을 조율하는 것) |
| Docker swarm | 도커 오케스트레이션 툴 중 하나로 분산 애플리케이션을 쉽게 배포하고 관리할 수 있는 기술 |
| 클러스터화 | 여러 대의 컴퓨터나 서버를 하나로 묶어 하나의 시스템처럼 동작하게 만든 컴퓨팅 환경 |
| 롤아웃/롤백 | 소프트웨어나 서비스의 업데이트나 배포 과정에서 새로운 버전으로 전환하는 것(롤아웃)과 문제가 발생했을 때 이전 버전으로 돌아가는 것(롤백) |
| DNS | 도메인 이름을 IP 주소로 변환하여 컴퓨터나 장치들이 인터넷에 연결되어 있는 다른 장치들을 찾을 수 있도록 돕는 인터넷 프로토콜 |
| 라우팅 | 여러 개의 네트워크를 연결하여 인터넷과 같은 대규모 네트워크를 구성 해주는 기술 |
| 로드밸런싱 | 여러 대의 서버에 트래픽을 분산시켜 부하를 분산시키고, 안정적으로 서비스를 제공하는 기술 |
| 퍼블릭 클라우드 |
인터넷을 통해 누구나 이용 가능한 클라우드 서비스로, 인프라와 리소스를 외부 서비스 제공업체에서 제공하고 관리 |
| Nginx | 무료 오픈 소스 웹 서버 소프트웨어로, 웹 서버, 리버스 프록시, 메일 프록시 등의 기능을 수행 |
| SSH | 인터넷에서 안전하게 원격 제어를 가능케 하는 프로토콜로, 암호화 기술을 사용하여 통신을 보호 |
| Prometheus | 오픈소스 모니터링 시스템. 애플리케이션, 시스템, 서비스 등을 모니터링할 수 있으며, 다양한 메트릭을 수집, 저장하고 조회할 수 있다 |
| Jenkins | 오픈소스 지속적인 통합(CI) 서버. 애플리케이션 개발에서 빌드, 테스트, 배포 등의 과정을 자동화할 수 있으며, 다양한 플러그인을 지원하여 기능을 확장할 수 있다 |
| OAuth | 사용자 인증을 위한 오픈 표준 프로토콜로, 웹이나 앱 등에서 다른 서비스의 정보나 기능을 사용할 수 있도록 권한 부여를 관리 |
| 노드 (node) |
서버로서의 노드는 클라이언트 요청을 처리하고, 다른 컴퓨터나 디바이스와 연결하여 네트워크에서 데이터를 주고받을 수 있는 컴퓨터나 장치 |
| MSA (Micro Service Architecture) | 마이크로서비스 아키텍처의 약어로, 작고 독립적인 서비스 단위로 구성된 분산 시스템 아키텍처를 의 |
| Kubernetes Control Plane |
쿠버네티스 클러스터에서 마스터 컴포넌트들이 실행되는 노드 그룹으로, 클러스터의 전반적인 상태 및 구성, 스케줄링, 배포, 업데이트, 모니터링 등의 관리 작업을 수행 |
| 워크로드 | 시스템에서 실행되는 작업을 의미하며, 컴퓨터의 CPU, 메모리, 디스크 등의 리소스를 사용하여 작업을 수행 |
| 모니터링 | 시스템 또는 프로세스를 지속적으로 감시하고 분석하여 성능, 가용성, 안정성, 보안 등을 평가하고 문제를 신속하게 해결하기 위한 작업 |
| 프록시 | 클라이언트와 서버 사이에서 요청과 응답을 전달하는 중간 서버로, 클라이언트의 IP를 숨기고 보안을 강화하거나 캐싱 등의 기능을 수행 |
| Flannel | 쿠버네티스 클러스터에서 사용하는 네트워크 솔루션 중 하나 |
| 워크플로우 | 업무나 작업의 진행 과정을 시각적으로 표현하여 보여주는 것으로, 업무의 흐름을 파악하고 관리하기 위한 방법 |
| manifest 파일 | 쿠버네티스에서 어플리케이션 배포에 필요한 설정 정보를 담은 YAML 또는 JSON 파 |
| YAML 형식 | 데이터를 인간이 쉽게 읽고 작성할 수 있도록 디자인된 경량 마크업 언어로, 키-값 쌍으로 이루어진 데이터 집합을 표현하는 포맷 |
| kubectl 명령어 | 쿠버네티스 클러스터에서 리소스를 생성하고 관리하기 위한 커맨드 라인 인터페이스 도구 |
| Kubernetes API schema | 쿠버네티스 API 서버가 제공하는 리소스의 스팩(Spec)과 상태(Status)를 정의하는 YAML 파일 |
| 스케줄링 | 컴퓨터 자원의 할당과 작업 처리 순서를 결정하는 작업 |
| 라우팅 | 서로 다른 네트워크를 연결 해주는 과정 |
| Vanilla | 소프트웨어 산업에서 제품이나 소프트웨어 패키지의 표준 버전을 가리키는 용어 |
| Swap Memory | 운영 체제가 하드 디스크 공간을 사용하여 사용 가능한 RAM을 보완할 수 있도록 하는 가상 메모리의 한 유형 |
쿠버네티스 개요
쿠버네티스 개념
컨테이너란?
전통적으로 물리적인 서버에서 애플리케이션을 실행 하였다. 이 방법은 하나의 물리적인 서버에 애플리케이션을 통제로 배포 하는 방법이였다. 이 방법은 서버의 리소스 관리, 애플리케이션 유지 보수 및 업데이트 같은 중요한 면들이 어렵고 비용이 많이 들었다. 이러한 어려움을 해결하기 위해 가상화 (Virtualization)가 도입 되었다. 단일한 물리적 서버의 CPU에서 여러 대의 가상머신 (Virtual Machine)을 실행하고, 물리적인 서버의 리소스를 최대한 사용 할 수 있었다. 하지만 한 가상머신당 새로운 OS(Operating System)가 존재 하여 애플리케이션 배포 및 리소스 면에서는 물리적인 서버와는 다른 이점이 없었다. 그래서 나온 컨테이너는 프로세스 단위의 격리 환경을 조성하고 있어 상호 간의 의존도를 낮추었다. 그 외 컨테이너는 호스트 서버의 OS를 그대로 사용하기 때문에 VM보다 훨씬 사이즈가 작고, 배포가 빠르고, 성능 손실은 거의 없었다.

컨테이너로 서비스를 제공하기 전 알아야 될 애플리케이션 배포의 형태들이 있다. 모놀리식(monolithic) 애플리케이션은 하나의 큰 애플리케이션으로, 모든 기능이 하나의 코드베이스에서 동작한다. 예를 들면 LAMP (Linux, Apache, MySQL, PHP) 스택을 사용하는 웹 서비스가 있다. 이러한 모놀리식 애플리케이션은 복잡하고 무거워지는 경향이 있다. 반면에, 컨테이너화된 애플리케이션은 애플리케이션을 실행하는 데 필요한 모든 것을 포함하고 있는 작은 패키지인 컨테이너 안에 애플리케이션을 묶는 것이고 이를 통해 애플리케이션을 더욱 효율적으로 실행할 수 있다. 컨테이너화된 애플리케이션의 예시로는 Docker, Podman, LXC와 같은 컨테이너화 기술을 사용하는 웹 서비스, 데이터베이스, 애플리케이션, 마이크로서비스 등이 있다.
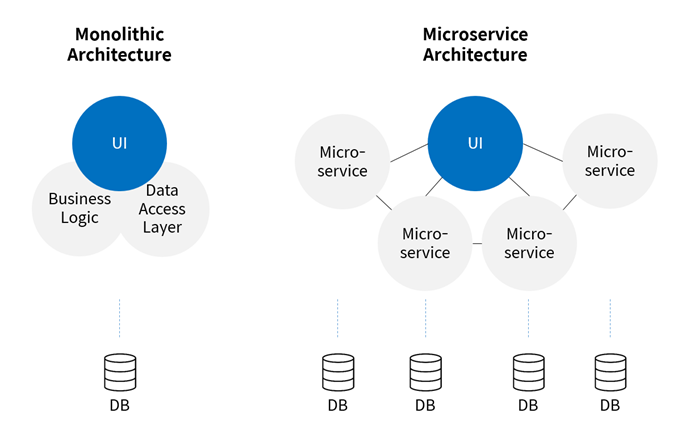
컨테이너화된 서비스
다양한 컨테이너 런타임 기술이 존재하지만, 그중에 도커(Docker)가 표준으로 여겨지고 있다. 만약에 도커 컨테이너로 마이크로서비스 형태의 애플리케이션을 배포 하게 된다면, 하나의 도커 이미지 안에 서비스 운영에 필요한 모든 것들이 들어 있어 개발자들이 손쉽게 협업을 할 수가 있다. 또한 서비스 운영 환경과 개발 환경의 느슨한 결합으로 한쪽의 에러에도 다른 한쪽은 작업을 계속해서 이어 나갈 수가 있다. 도커컨테이너는 배포가 쉽고 빠르며 시스템 의존성을 쉽게 업그레이드할 수 있어 스케일 아웃에 용이하다. CPU limit, Memory limit 등의 시스템 자원을 효율적으로 활용할 수가 있고 무엇보다도 가상머신 보다 성능 면에서 뛰어나다. 하지만 이렇게 컨테이너화된 애플리케이션도 역시 관리를 해야 한다. 만약에 컨테이너화된 애플리케이션이 다운이 되면 직접 재실행 시켜야 된다. 전통적인 방식과 VM보다 관리가 용이하지만 컨테이너의 스케일 아웃 장점 때문에 관리해야 하는 컨테이너 수가 많아지게 되면 관리 와 운영에 어려움이 따르게 된다.
쿠버네티스의 등장
각각 독립적으로 배치된 컨테이너를 연결, 관리 및 확장하면서 요소들 전체가 하나로 실행 되도록 해야 한다. 이렇게 다수의 컨테이너 실행을 관리해주는 것을 컨테이너 오케스트레이션 이라고 부른다. 오케스트레이션(Orchestration)은 수많은 연주자들이 지휘에 맞춰 연주하는 것을 "오케스트라"라고 한다. 오케스트레이션은 음악에서 다양한 음악적 요소들을 조화롭게 배열하고 조율하여 완성도 높은 작품을 만들어내는 과정이고, 컨테이너 오케스트레이션 또한 다양한 컨테이너들을 효율적으로 관리하고 조율하여 원활한 애플리케이션 운영을 가능하게 한다. 마치 오케스트레이션의 역할처럼, 컨테이너 오케스트레이션은 각각의 요소를 조화롭게 배치하고 조율하여 시스템 전체가 조화롭게 동작하도록 돕는다. 쿠버네티스는 구글이 개발한 오케스트레이션 엔진으로서 컨테이너를 쉽고 빠르게 배포/확장하고 관리를 자동화해주는 오픈소스 플랫폼이다. 쿠버네티스는 구글에서 내부적으로 사용하던 Borg 시스템에서 발전되었고, 2014년에 쿠버네티스 프로젝트를 오픈 소스 화 했다. Kubernetes를 가끔 K8s라고 표현한다. K8s는 "K"와 "s"와 그 사이에 있는 8글자를 나타내는 약식 표기이다.
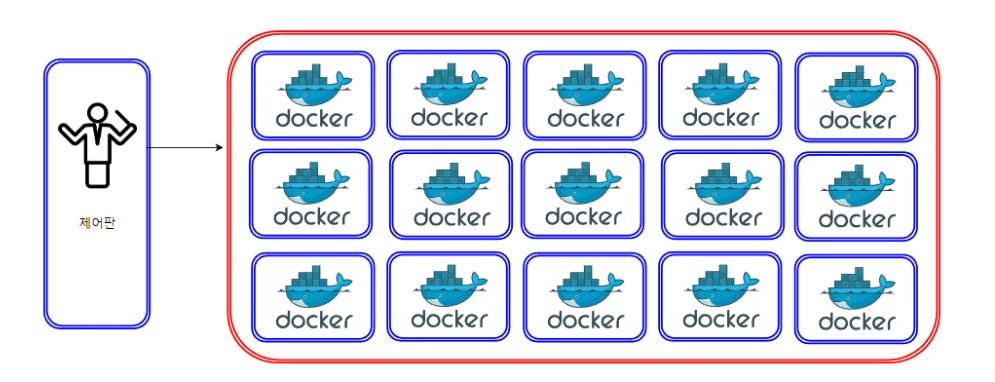
실제 프로덕션 환경에서의 애플리케이션들은 여러 컨테이너에 걸쳐 있으며 이러한 컨테이너는 여러 서버 호스트에 배포되어야 한다. 이 때문에 컨테이너를 위한 보안은 멀티 레이어 구조로 되어 있고 복잡할 수 있다. 쿠버네티스는 이러한 워크로드를 위해 규모에 맞는 컨테이너를 배포하는 데 필요한 오케스트레이션 및 관리 기능을 제공한다. 쿠버네티스 오케스트레이션을 사용하면 여러 컨테이너에 걸쳐 애플리케이션 서비스를 구축하고 클러스터 전체에서 컨테이너의 일정을 계획하고 이러한 컨테이너를 확장하여 컨테이너의 상태를 지속적으로 관리할 수 있다. 그것 뿐만이 아니라 컨테이너 오케스트레이션 도구를 사용하면 자동화된 배포 및 스케일링, 롤아웃/롤백 및 컨테이너 복구 작업을 구현 할 수가 있다는 장점들이 존재한다.
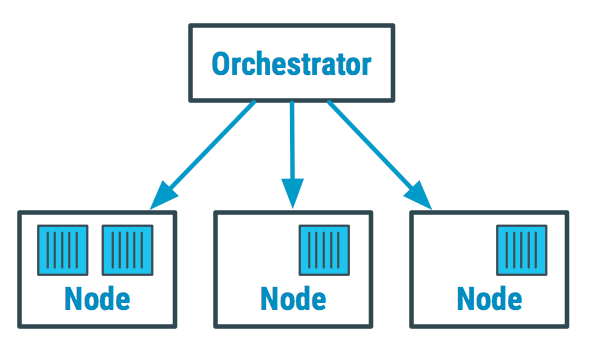
쿠버네티스 주요 기능
-
Self-healing: 쿠버네티스는 제대로 실행되지 않는 컨테이너를 자동으로 재시작하거나 교체할 수 있다.
-
Automated Rollouts & Rollbacks: 원하는 배포 상태에 맞는 속도로 현재 배포 상태를 변경할 수 있다.
-
Service Discovery & Load Balancing: DNS 또는 IP 주소를 사용하여 클러스터 내의 컨테이너를 외부에 노출시킬 수 있다. 네트워크 트래픽이 많은 서비스의 경우, 안정적인 서비스 운영을 위해 네트워크 트래픽을 로드밸런싱도 가능 하다.
-
Storage Orchestration: 로컬 스토리지 서버와 퍼블릭 클라우드 스토리지 서비스를 연결하여 사용할 수 있다. 외부 스토리지 서버 자원을 쉽게 사용할 수 있으며, 데이터 지속성을 보장할 수 있다.
-
Secret and Configuration Management: 비밀번호, SSH Key, OAuth 토큰과 같은 중요한 정보를 안전하게 저장하고 관리할 수 있다. 컨테이너 구성 정보가 변경되면, 쿠버네티스는 컨테이너 이미지를 재구성하지 않고 구성 정보의 변경 사항을 반영하여 배포 및 업데이트할 수 있다.
-
Automatic Bin Packing: 컨테이너 운영에 필요한 자원 사용률을 수신하고 가장 적합한 클러스터 노드를 제공한다.

클러스터 구성 요소 소개
쿠버네티스 중요 요소들을 논리적으로 간단하게 설명 하고 나눤다면:
| Hardware(하드웨어) | Node |
|---|---|
| Orchestration(오케스트레이션) | Deployment, Job, CronJob, StatefulSet, DaemonSet |
| Configuration(구성) | ConfigMap, Secret |
| Persistence(지속성) | PersistentVolume, PersistentVolumeClaim(PVC) |
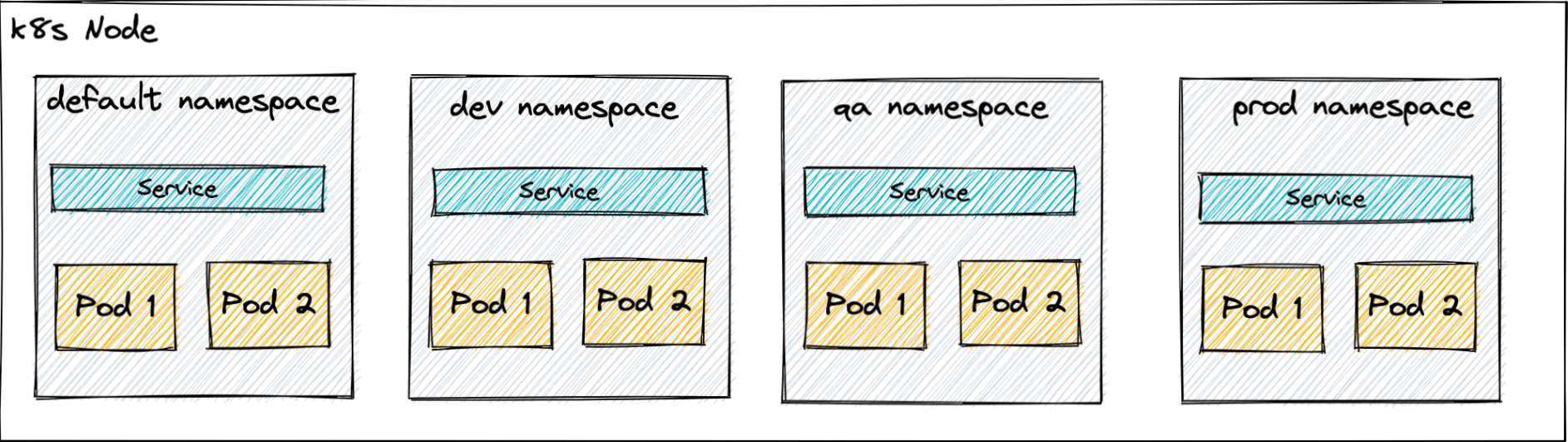
| AccessControl(접근 제어) | Namespace, ServiceAccount, Role, ClusterRole |
| Exposure(외부 노출) | Service, Ingress |
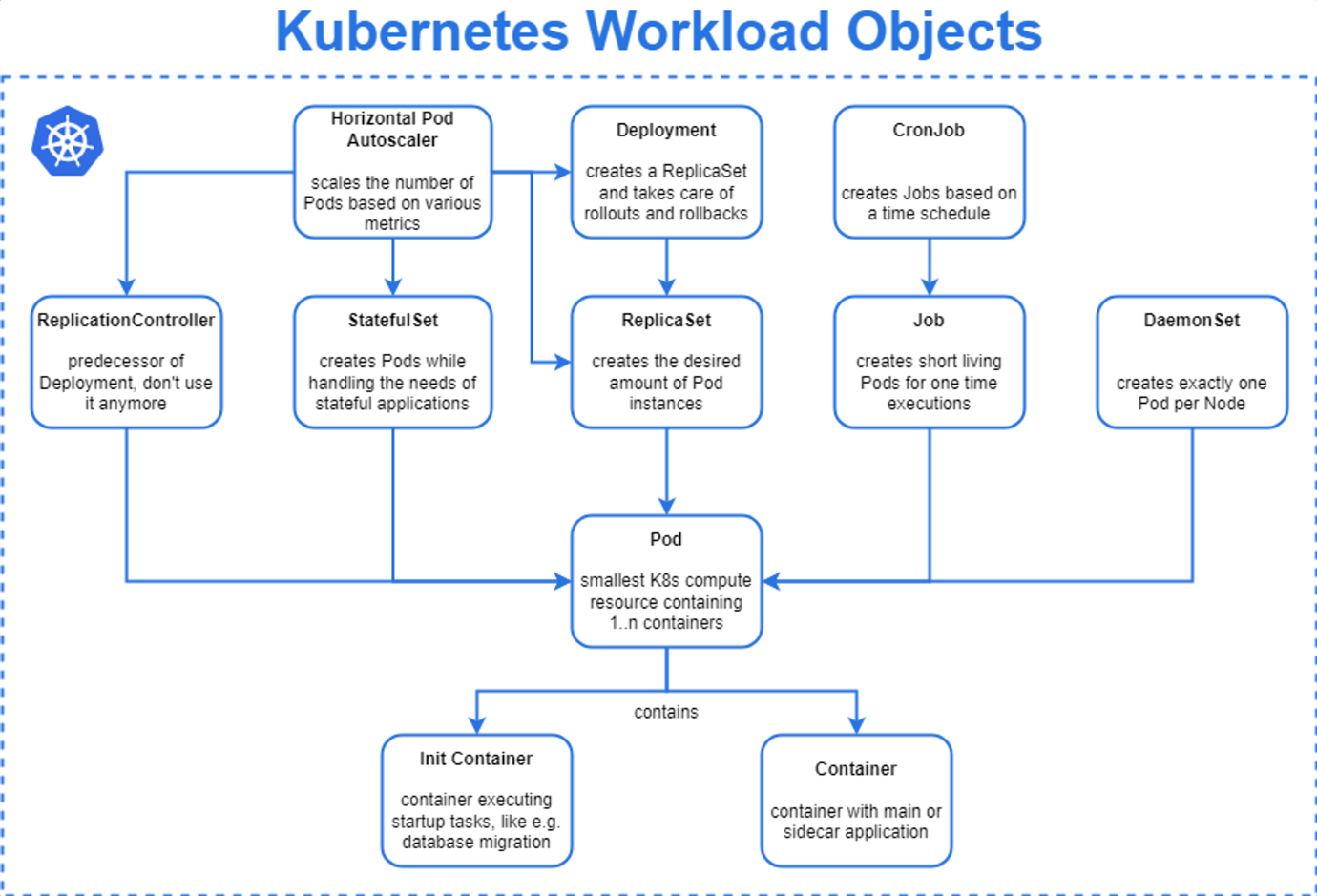
Node
클러스터 내에서 하드웨어 역할을 한다. 컨테이너화된 워크로드를 실행할 수 있는 물리적 또는 가상의 서버이다. 쿠버네티스 클러스터 내에서 노드는 워커(Worker) 및 마스터(Master)노드로 나눠줘 있다. 각 노드는 클러스터의 일부가되어 컨테이너화된 애플리케이션을 실행하고 클러스터 내에서 다른 노드와 통신한다.
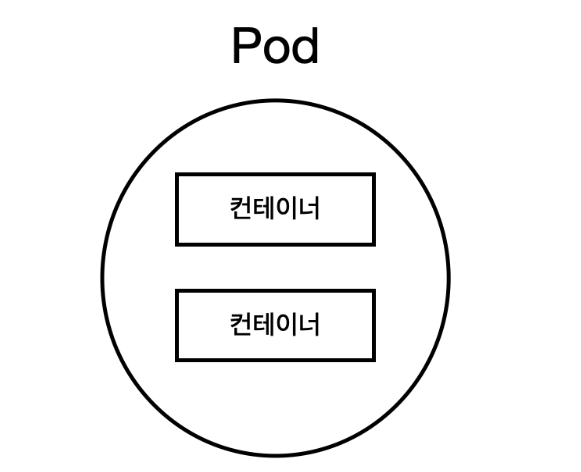
Pod
쿠버네티스에서는 애플리케이션을 배포할 수 있는 최소 단위인 파드(Pod)라는 개념을 제공한다. 파드는 하나 이상의 컨테이너를 포함할 수 있으며, 같은 파드 안에 있는 컨테이너는 동일한 호스트에서 실행된다.
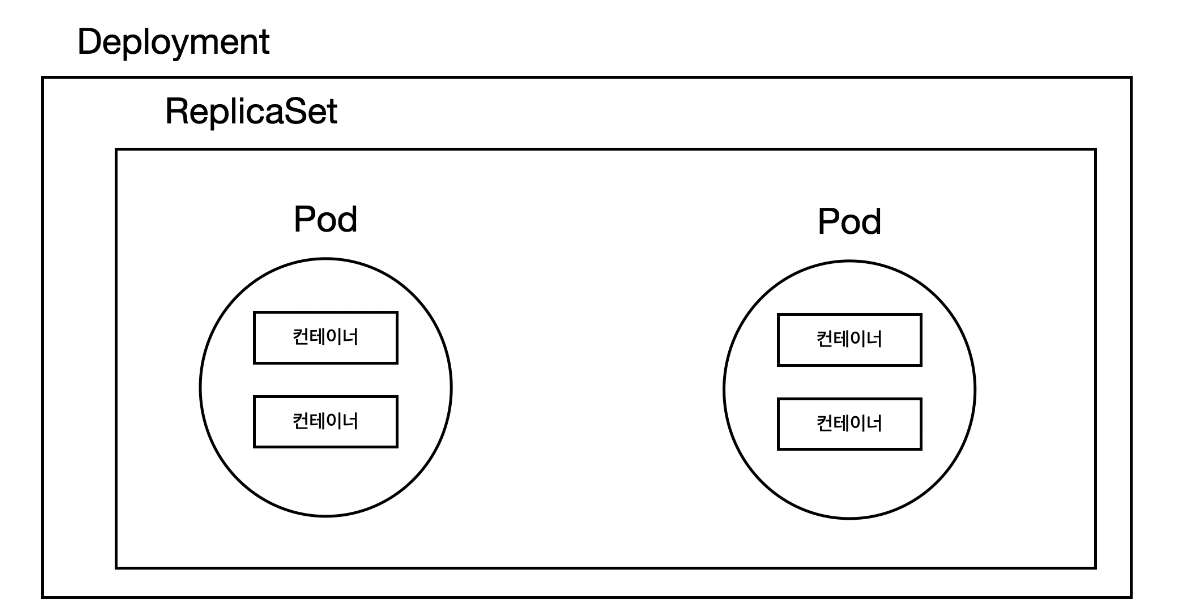
Deployment
레플리카셋(ReplicaSet)을 이용하여 애플리케이션의 배포를 관리한다. Deployment을 사용하면 롤아웃 및 롤백, 업데이트, 스케일링 등을 쉽게 처리할 수 있다.
ReplicaSet
Pod의 수를 관리하고, 원하는 수의 Pod가 항상 실행되도록 유지하는 역할을 하는 오브젝트. ReplicaSet은 주로 Pod을 생성하고, 감시하고, Pod가 정상적으로 실행되지 않을 경우 다른 Pod으로 대체하는 작업을 수행한다.
Job
일회성 작업을 실행하며, 해당 작업이 성공적으로 완료될 때까지 실행을 유지하는 쿠버네티스 리소스. 일반적으로 배치 작업 또는 데이터 처리와 같은 일회성 작업을 수행하는 데 사용된다.
CronJob
쿠버네티스에서 제공하는 오브젝트 중 하나로, 정해진 시간 간격으로 반복적으로 실행되는 Job을 생성하기 위해 사용된다. CronJob을 사용하면 정기적인 작업을 반복적으로 실행할 수 있으며, 예를 들어 백업, 데이터베이스 업데이트, 인덱스 생성 등의 작업을 스케줄링할 수 있다.
StatefulSet
StatefulSet은 ReplicaSet의 확장된 버전이다. 상태(state)를 가지는 애플리케이션을 관리하기 위해 사용된다. 일반적인 Deployment와는 달리, StatefulSet은 각 Pod에 고유한 식별자를 부여하며, Pod가 재시작되더라도 동일한 식별자를 유지한다. 이로 인해 StatefulSet은 데이터베이스나 메시지와 같이 상태가 중요한 애플리케이션을 배포하는 데 적합하다.
HPA(Horizontal Pod Autoscaler)
HPA는 쿠버네티스 클러스터에서 현재 실행 중인 파드 수를 모니터링하고, 이에 대한 CPU나 메모리 사용량 등의 지표를 기반으로 파드 수를 자동으로 조절한다. 이를 통해 클러스터에서 파드 수를 최적화하고, 예상치 못한 트래픽 급증에 대응할 수 있도록 한다.
DaemonSet
모든 노드에 특정 파드를 실행하도록 하는 Kubernetes 오브젝트. 이러한 파드들은 클러스터의 모든 노드에서 실행되며, 노드가 추가될 때 자동으로 파드가 추가되며, 노드가 제거될 때 자동으로 파드도 제거된다. 로그 수집 에이전트나 모니터링 에이전트 실행할때 활용할 수 있다.
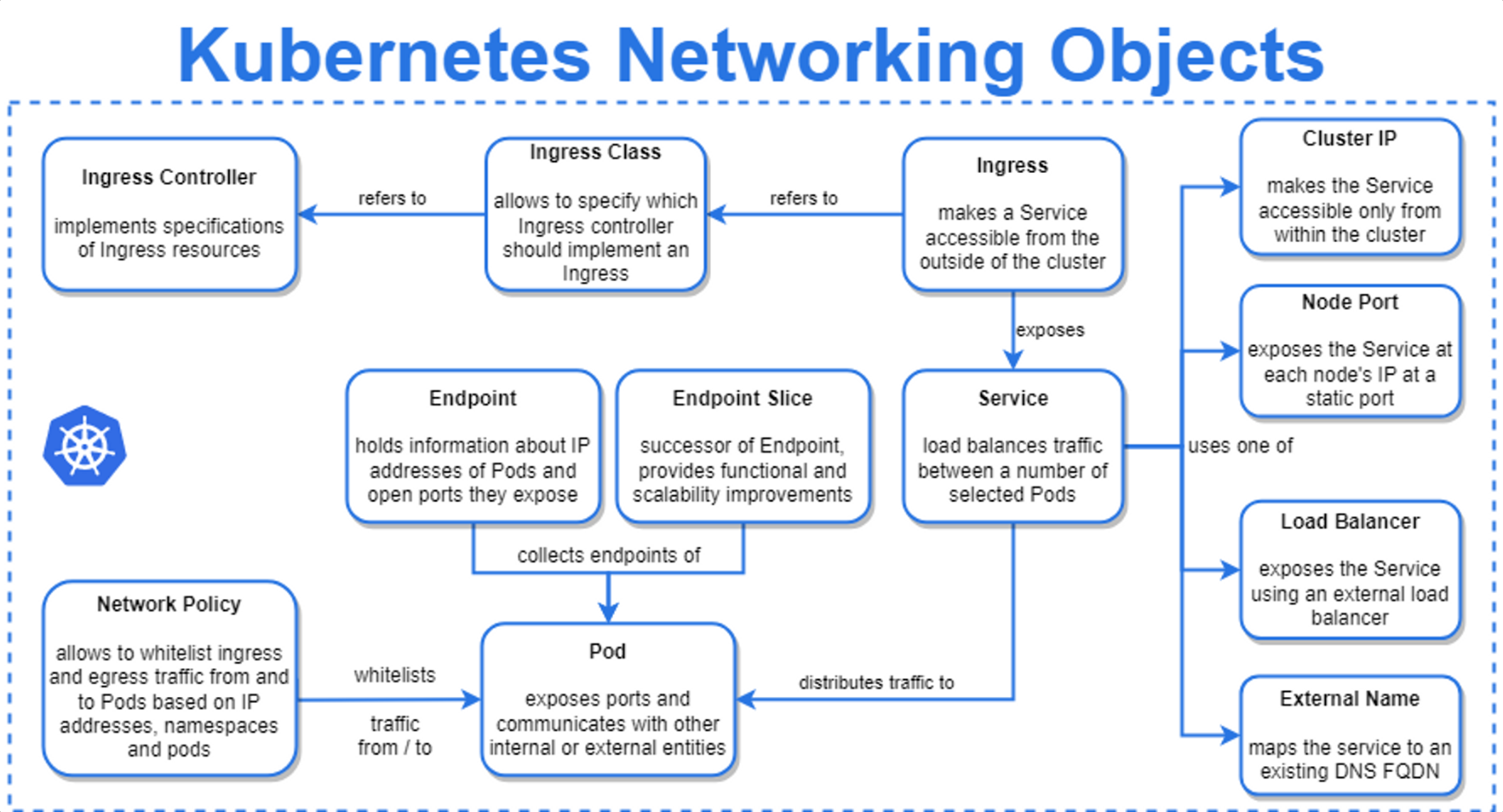
Service
하나 이상의 Pod 집합에 대한 네트워크 엔드포인트를 정의하고 안정적인 DNS 이름을 제공하는 Kubernetes 오브젝트. 서비스 옵젝트는 파드 집합에 대한 네트워크 엔드포인트를 제공하며, 애플리케이션에 접근할 수 있는 방법을 제공한다. 서비스 옵젝트에는 ClusterIP, NodePort, LoadBalancer 및 ExternalName이 있다.
Ingress & Ingress Controller
클러스터 내부에 있는 서비스에 접근하기 위한 외부에서의 진입점을 제공하는 쿠버네티스 리소스 옵젝트. HTTP, HTTPS, 그리고 TLS 등의 프로토콜을 지원하며, 라우팅 규칙을 설정하여 클러스터 내부의 다양한 서비스에 대한 접근을 제어할 수 있다.
인그레스는 Ingress Controller와 함께 사용되며, 인그레스 규칙을 수신하여 요청을 올바른 서비스로 라우팅한다. Ingress Controller는 클라우드 제공 업체에서 제공하는 로드밸런서, Nginx, Traefik 등의 소프트웨어를 사용할 수 있다.
Volume
볼륨(Volume)은 컨테이너에서 사용할 수 있는 디스크 공간을 제공합니다. 파드 안에 있는 컨테이너는 볼륨을 공유할 수 있으며, 디스크에 저장된 데이터를 읽고 쓸 수 있습니다.
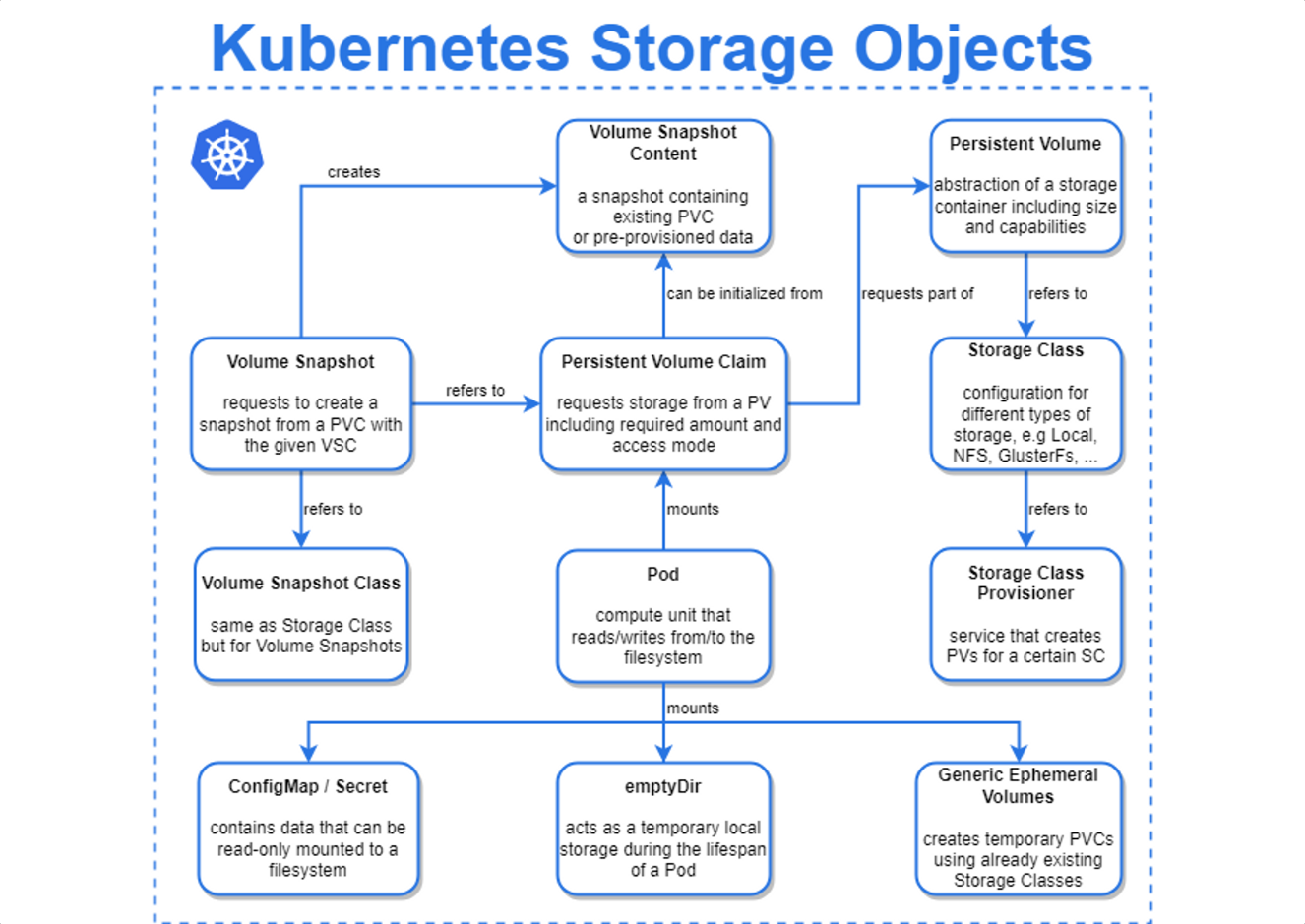
Persistent Volume Claim & Persistent Volume
Persistent Volume(PV)은 컨테이너화된 어플리케이션에서 사용될 수 있는, 클러스터 레벨에서 정의된 스토리지 볼륨이다. 이 스토리지 볼륨은 클러스터 안의 노드에 있는 물리적 스토리지와 매핑되어, 클러스터 안의 다른 오브젝트와 마찬가지로 클러스터 노드 사이에서 이동될 수 있다.
Persistent Volume Claim(PVC)은 어플리케이션에서 사용할 특정한 Persistent Volume을 요청하는 Kubernetes 오브젝트. 어플리케이션이 필요한 용량, 스토리지 클래스 및 액세스 모드 등을 정의하고 PVC를 사용하여 해당 요청 사항을 표현한다. 이를 통해 어플리케이션은 실제 스토리지를 직접 다루지 않아도 되며, 볼륨에 대한 액세스를 안전하게 보호할 수 있다.
ConfigMap/Secret
애플리케이션에서 사용되는 환경변수, 설정 값 등과 같은 구성 데이터를 저장하는 쿠버네티스 옵젝트. ConfigMap과 Secret의 차이점은, Secret은 보안 데이터를 저장하는데 사용되고, ConfigMap은 설정값 및 환경변수 데이터를 저장한다.
Namespace
쿠버네티스 클러스터 안에서 리소스들을 논리적인 그룹으로 분류하기 위한 추상화된 방법. 각각의 네임스페이스는 자신만의 리소스를 가질 수 있으며, 다른 네임스페이스의 리소스와 격리된다. 즉 Namespace는 클러스터를 논리적으로 분리한다.
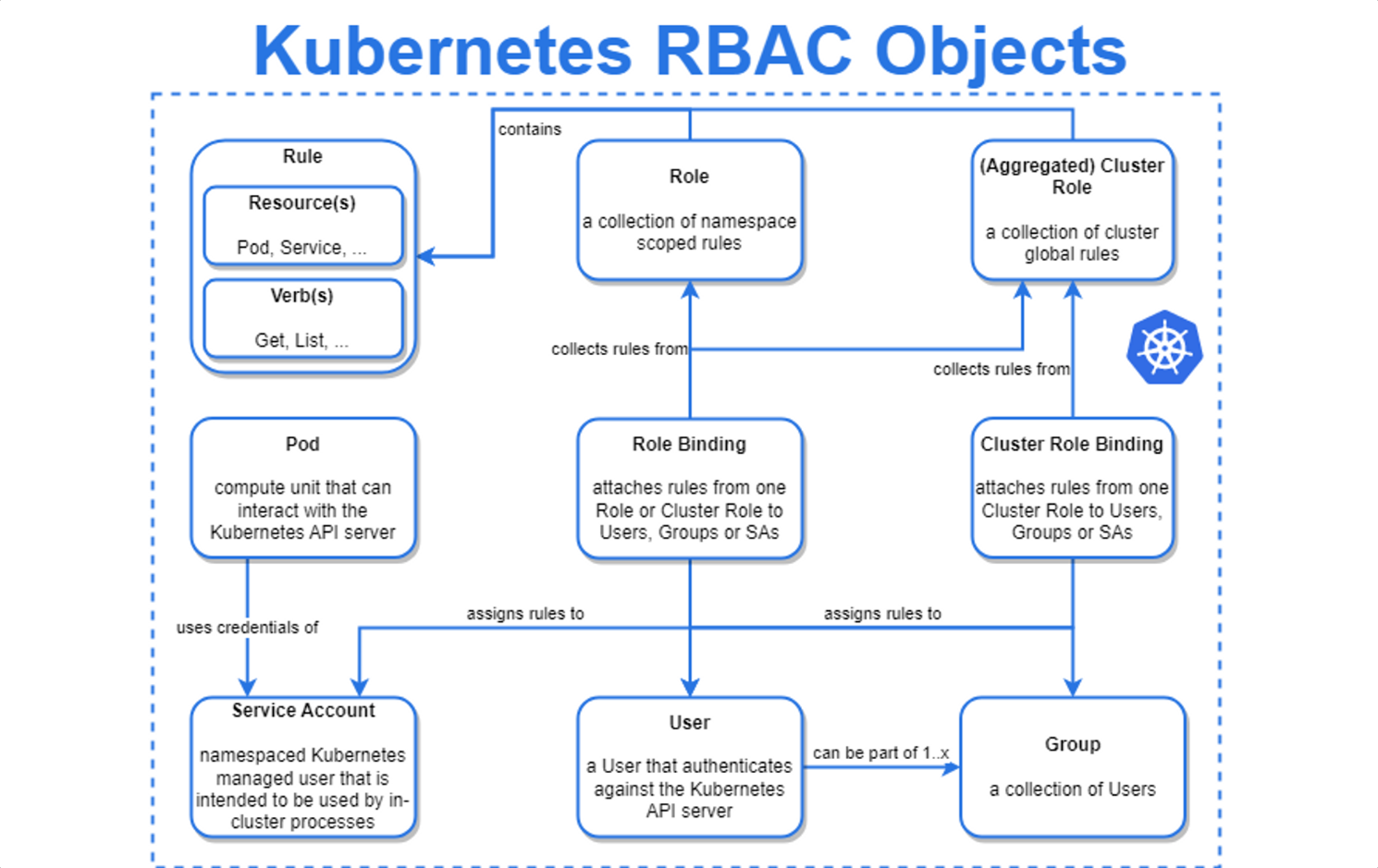
Role
Role은 사용자 또는 서비스 계정이 클러스터 내에서 수행할 수 있는 작업 집합을 정의하는 Kubernetes 리소스 중 하나. Role을 사용하여 사용자 또는 서비스 계정에 권한을 할당할 수 있다. Role은 RoleBinding과 함께 사용되며, RoleBinding은 특정 사용자 또는 서비스 계정에 Role을 할당하는 데 사용된다. 즉, RoleBinding은 Role을 사용하여 사용자 또는 서비스 계정에 권한을 부여한다.
ClusterRole
클러스터 자체에서 동작하며 권한을 부여하는 권한 모음이다. 예를 들어, 클러스터 관리자는 클러스터 전체에 대한 역할을 만들어 로그 및 이벤트를 볼 수 있지만, 개발자 역할은 각 네임스페이스에서 사용할 수 있는 권한만 가질 수 있다. 이러한 역할은 클러스터의 모든 네임스페이스에서 권한을 가질 수 있다.
ServiceAccount
클러스터 내부에서 사용자나 프로세스에게 권한을 부여하기 위한 리소스. 쿠버네티스의 계정에는 2종류(유저 어카운트, 서비스 어카운트)가 존재. UserAccount는 엔지니어/개발자 등이 클러스터를 운영하는데 활용. ServiceAccount는 쿠버네티스 서비스 또는 3rd party 서비스(Prometheus, Jenkins등)가 사용하는 계정. 각 네임스페이스마다 디폴트 ServiceAccount가 있다. 이 디폴트 ServiceAccount는 해당 네임스페이스의 모든 파드에 대해 기본적으로 사용되며, 이외의 ServiceAccount는 수동으로 생성하고 사용해야한다.
쿠버네티스 아키텍처
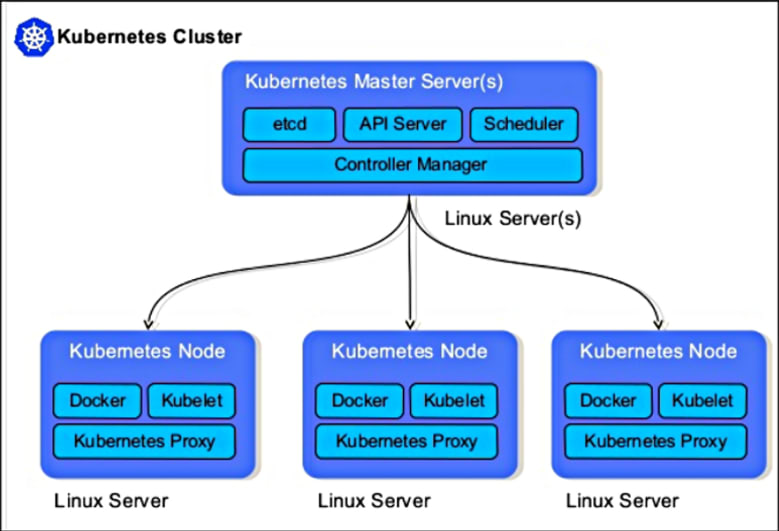
쿠버네티스 클러스터는 MSA(Micro Service Architecture) 구조에서 컨테이너 배포와 서비스 장애 복구와 같은 컨테이너 기반 서비스 운영에 필요한 대부분의 기능을 지원한다. 쿠버네티스 클러스터는 기본적으로 마스터와 워커 노드 형태로 구성된다. 마스터 노드는 물론 Control Plane(Orchestra)의 역할, 쉽게 말하면 제어판과 비슷한 역할, 그리고 워커 노드에서는 실제 워크로드가 실행 된다.
마스터 노드
마스터 노드에는 "Kubernetes Control Plane"을 구성하는 다양한 핵심 구성 요소가 있고, 관리적 작업에만 사용된다. 마스터 노드는 전체 클러스터를 관리하며, 워커노드에 예약된 작업을 할당하고 시스템의 상태를 관리한다. 본질적으로 쿠버네티스 클러스터의 뇌라고 생각하면 된다. 쿠버네티스 마스터 노드의 중요한 구성요소는 아래와 같다: `
- API Server:- 클러스터 내부 리소스를 제어하는 API를 제공하는 서버를 의미한다. 쿠버네티스의 리소스 정보를 관리하기 위한 프론트엔드 REST API. 각 컴포턴트로 부터 리소스 정보를 받아 데이터스토어(etcd)에 저장하는 역할을 갖고 있다. 다른 컴포넌트는 API Server를 통해 이 etcd 정보에 액세스한다. 개발자 혹은 시스템 관리자가 이 Server에 액세스하려면 kubectl 명령을 사용한다. 또 애플리케이션 안에서 API Server를 호출할 수도 있다.
- Scheduler:- 쿠버네티스 리소스에 대한 리소스 요청을 예약하는 역할을 한다. 스케줄러는 노드에 할당되어 있지 않은 Pod에 대해 쿠버네티스 클러스터의 상태를 확인하고 빈 공간을 갖고 있는 노드를 찾아 Pod를 실행 시킨다. 클러스터를 구성하는 워커 노드의 상태를 검토하여 리소스 할당이 필요한 리소스 요청을 처리할 최적의 노드를 선택 한다.
- Controller-manager:- 쿠버네티스 클러스터의 컴포넌트들의 상태를 모니터링 하고 본래 되어야 할 상태를 유지하는 백엔드 컴포넌트. 정의 파일에서 정의한 것과 실제 노드나 컨테이너에서 작동하고 있는 상태를 모아서 관리 한다.
- etcd(데이터스토어):- 쿠버네티스 클러스터의 구성 데이터를 저장하기 위해 사용되는 분산 키-값 저장소다. 노드 상태 및 서비스 상태와 같은 쿠버네티스 클러스터의 상태를 저장하는 데 사용된다. Key-Value형으로 관리하며 어떤 Pod를 어떻게 배치할지와 같은 정보를 갖고 있어서 API Server가 이를 참조한다. 이 데이터스토어는 마스터 서버에서 분리 시킬 수도 있다.
워커 노드
이전에는 '미니언' 이라고 불렸으며, 워커 노드는 쿠버네티스 클러스터의 애플리케이션 및 워크로드를 실행한다. 컨테이너를 실행하고 컨테이너 런타임 환경을 처리하는 역할을 한다. 워커 노드의 핵심 구성 요소는 아래와 같다:
- Kubelet:- 쿠버네티스의 주요 구성 요소로, 워커 노드에서 API 서버와 통신하여 쿠버네티스 클러스터에 노드를 등록한다. 파드의 라이프 사이클을 관리하고 노드 및 파드의 상태를 모니터링한다.
- Kube-proxy:- 모든 워커 노드에서 실행되며 각 노드에 대한 네트워크 규칙을 생성 및 관리하는 네트워크 프록시 역할을 한다. K8s 프라이빗 네트워크 내에서 적절한 서비스 또는 응용 프로그램으로 요청을 전달하는 reverse 프록시와 같은 역할을 수행 한다.
- Container runtime:- 모든 워커 노드에서 실행되며 컨테이너를 실행하고 관리하는 역할을 한다 (예: Docker).

쿠버네티스 네트워킹
컨테이너 네트워크 모델
쿠버네티스는 컨테이너화된 애플리케이션을 배포하고 관리하기 위한 오픈 소스 컨테이너 오케스트레이션 플랫폼이다. 이를 통해 여러 개의 컨테이너가 클러스터 상에서 효율적으로 통신하고 네트워크 리소스를 공유할 수 있다.
1. 파드 (Pod)
쿠버네티스의 가장 작은 배포 단위인 파드는 하나 이상의 컨테이너 그룹을 포함 한다. 파드 내의 컨테이너들은 동일한 네트워크 네임스페이스와 IP 주소를 공유 한다. 즉, 파드 내의 컨테이너들은 로컬 호스트처럼 서로 통신할 수 있다.
2. 서비스 (Service)
서비스는 파드 집합에 대한 안정적인 네트워크 엔드포인트를 제공하는 추상화 이다. 서비스는 일정한 IP 주소와 포트를 가지며, 클러스터 내부 또는 외부에서 접근 가능한 엔드포인트로서 동작 한다. 서비스를 통해 다른 파드나 서비스와 통신할 수 있다.
3. 서비스 디스커버리 (Service Discovery)
서비스 디스커버리는 클라이언트 애플리케이션이 서비스를 찾고 접근할 수 있는 기능을 제공 한다. Kubernetes는 DNS(Domain Name System)를 사용하여 서비스를 검색하고 해석 한다. 클라이언트는 서비스 이름을 사용하여 해당 서비스에 연결할 수 있다.
4. 클러스터 내부 통신
쿠버네티스는 클러스터 내의 파드는 기본적으로 같은 네트워크에 속하므로 서로의 IP 주소를 직접 사용하여 통신할 수 있다. 이는 로컬 호스트에서 실행되는 컨테이너들 사이의 통신과 유사한 방식이다. 파드 간 통신은 내부 IP 주소를 사용하며, 네트워크 리소스는 클러스터 내에서 공유 된다.
5. 클러스터 외부 통신
클러스터 외부에서 파드에 접근하려면 서비스를 통해 노출해야 한다. 쿠버네티스는 로드 밸런서(Load Balancer), 노드 포트(NodePort), 인그레스(Ingress) 등 다양한 방법을 제공하여 클러스터 외부로 트래픽을 노출할 수 있다.
6. 네트워크 정책 (Network Policies)
쿠버네티스는 네트워크 정책을 통해 파드 간의 통신을 제한하고 제어할 수 있는 기능을 제공 한다. 네트워크 정책은 파드의 네트워크 트래픽을 제어하는 규칙을 정의하며, 보안 및 네트워크 분리를 위해 사용 된다.
Pod 네트워킹
- Pod IP 주소 할당
- Pod 간 통신
서비스 네트워킹
Deployment를 통해 생성된 파드의 IP를 통해서 직접 접근할 수도 있지만, 파드가 재생성될 경우 경우 IP가 영속적이지 않기 때문에 변경될 수 있다는 점을 유의해야 한다. 여러 개의 Deployment를 하나의 완벽한 애플리케이션으로 연동하려면 파드 IP가 아닌 서로를 발견할 수 있는 방법이 필요하다.
서비스는 여러 개의 팟에 쉽게 접근할 수 있도록 도메인 이름을 부여하고, 로드 밸런서 기능을 수행하여 파드를 외부로 노출시켜준다.
서비스는 Cluster IP, NodePort, LoadBalancer 이렇게 3가지 타입이 있다.
먼저 ClusterIP의 대한 얘기 해보겠다.
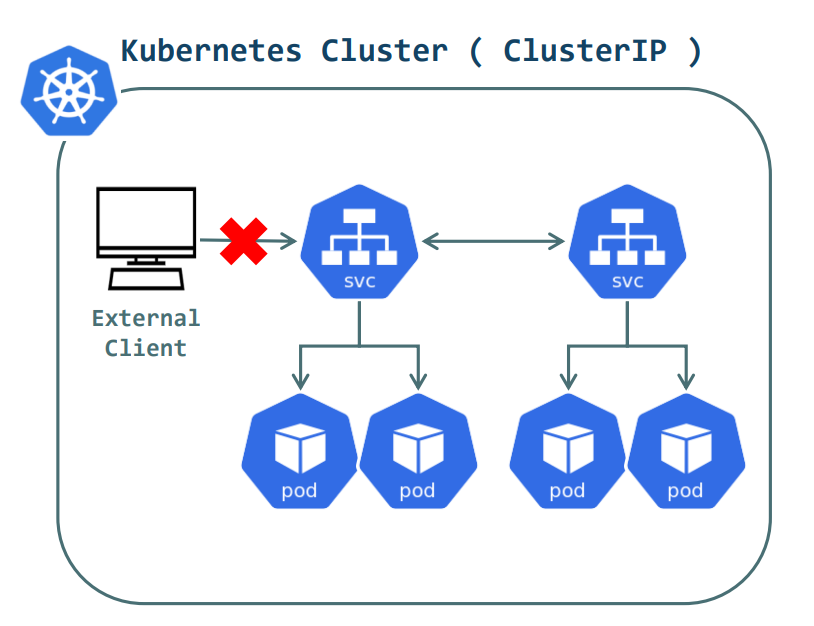
예시:
apiVersion: v1
kind: Service
metadata:
name: hostname-svc-clusterip
spec:
ports:
- name: web-port
port: 8080
targetPort: 80
selector:
app: webserver
type: ClusterIP
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: hostname-deployment
spec:
replicas: 3
selector:
matchLabels:
app: webserver
template:
metadata:
name: my-webserver
labels:
app: webserver
spec:
containers:
- name: my-webserver
image: waji97/test:v1
ports:
- containerPort: 80생성된 서비스는 쿠버네티스 내부에서만 사용할 수 있는 고유 IP(Cluster IP)를 할당 받는데, 6번 줄에 있는 ports:는 해당 IP의 어떤 포트를 사용해서 접근 가능한지 기입한다. 똑같은 필드에 있는 targetPort는 접근할 파드가 사용하고 있는 포트 번호를 나타낸다. 10번 줄에 있는 selector는 이 서비스에서 어떤 라벨을 가지는 파드에 접근할 수 있게 만들 것인지를 나타낸다. 이렇게 설정을 하면, 내부적으로 파드의 IP가 변경되어도 서비스를 통해 접근하게 되므로 상관없어질 것이다. Cluster IP는 외부에서 접근할 수가 없다.
이번에는 NodePort 타입이다
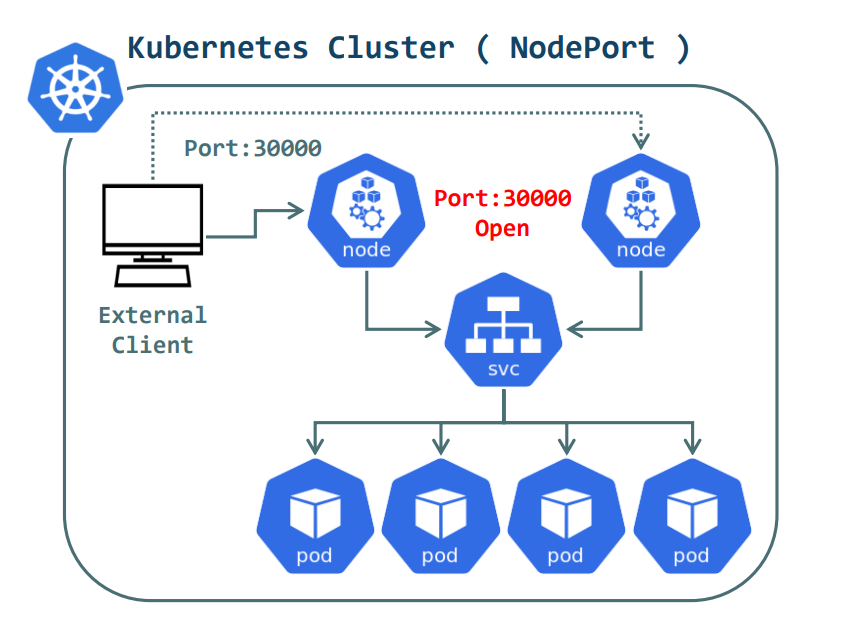
예시:
apiVersion: v1
kind: Service
metadata:
name: hostname-svc-nodeport
spec:
ports:
- name: web-port
port: 8080
targetPort: 80
selector:
app: webserver
type: NodePortManifest파일 형태는 거의 동일 하지만 마지막에 type:필드만 NodePort로 바뀐다. Cluster IP 타입일 때에는 단순히 파드에 연결해주는 것이었다. NodePort는 외부에서 어떤 노드든 간에 해당 노드의 IP에 접근하고 NodePort의 포트번호로 접근하기만 하면 해당 파드로 연결을 해준다. 포트는 30000 ~ 32767 중 랜덤으로 지정된다.
마지막에 있는 LoadBalancer 타입은 노드포트에 접근하게끔 로드밸런싱을 해주는 타입인데 클라우드 플랫폼 환경에서 주로 사용가능 하다. 예를 들어 AWS 클라우드 플랫폼에서 로드 밸런서 서비스를 지정 해주면, AWS상 로드밸런서가 자동 생성 된고 로드 밸런서 역할을 수행 한다(AWS EKS 클러스터가 설정 되어 있는 과정에서만). 그 외 Baremetal 환경에서는 오픈소스 Load Balancer인 MetalLB를 사용하여 쿠버네티스 클러스터에 Load Balancer를 별도로 구축 가능 하다. MetalLB는 간단하게 로드 밸런서 기능을 해주는 파드를 생성 해준다.

MetalLB에 대한 기본 정보-
- MetalLB는 L2모드와 BGP모드를 지원 한다
- BGP 모드는 실제 L3스위치 아니면 라우터를 사용하여 로드 밸런싱 기능을 사용 할 수 있다. 외부에서 라우터의 IP로 접속하면 실제 서비스로 연결 시켜준 되, 서비스가 파드로 연결 시켜준다.
- L2 모드는 클러스터 내부 전체 노드에 DaemonSet Controller를 이용하여 Speaker Pod를 구성하는 방식을 사용한다.
- Speaker Pod 중 Master를 선출하여 선출 된 Master에서 External-IP(외부 연결이 가능한 IP)를 관리한다.
- L2 모드는 Master Speaker에서 MetalLB 정보를 다른 Member Speaker Pod에 전달하기위해 ARP(Address Resolution Protocol)를 사용한다.
- MetalLB L2모드를 사용하기 위해서는 kube-proxy Pod에서 ARP 사용 허가를 해주어야 한다.
- 쿠버네티스 클러스터 내부의 모든 kube-proxy Pod에서 ARP 사용 허가를 해주어야 한다.
기본적인 MetalLB의 동작 흐름:
- NodePort가 speaker파드로 연결되고, speaker 파드들은 controller로 연결 된다.
- 외부에서 이 로드 밸런서의 IP로 접속하게 되면, 어느 노드든 상관 없이 speaker를 통해 controller로 연결되고, controller는 다시 NodePort로 분배해 준다.
- 그리고 NodePort가 내부의 실제 서비스로 다시 연결 해 준다.
- 최종적으로 이 서비스가 다시 파드로 연결 시켜준다.
BGP모드는 Border Gateway Protocol의 약자로 인터넷에서 라우팅 정보를 교환하고 관리하기 위해 사용 된다
ARP는 IP 주소와 MAC 주소 간의 매핑을 수행하는 네트워크 프로토콜이다
예시:
vi app.yaml
# 로드 밸런서 YAML 파일
apiVersion: v1
kind: Service
metadata:
name: nginx-loadbalancer
spec:
ports:
- name: web-port
port: 80
targetPort: 8080
selector:
app: webserver
type: LoadBalancer
---
# 웹 사이트 배포 YAML 파일
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest
ports:
- containerPort: 8080이렇게 YAML 파일을 적용 시킨 후 결과를 확인 하면
# YAML 파일 적용
kubectl apply -f app.yaml
# 모든 리소스 확인
kubectl get all
NAME READY STATUS RESTARTS AGE
pod/nginx-deployment-6f67db9747-l8shl 1/1 Running 0 6s
pod/nginx-deployment-6f67db9747-tcc8k 1/1 Running 0 6s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes ClusterIP 10.233.0.1 <none> 443/TCP 24h
service/nginx-loadbalancer LoadBalancer 10.233.8.88 <pending> 80:31810/TCP 6s현재 VM을 사용 하여 예시를 사용 하였기 때문에 로드 밸런서가 실제로 생성 되지 않는다. 그렇기 떄문에 EXTERNAL-IP도 아직 <pending> 상태이고 on-premise 환경에서 사용되는 로드 밸런서인 MetalLB를 사용 해야 한다. MetalLB를 설치 하는 방식은 Helm 차트, 매니페스트 파일 그리고 Kubespray로 통해 할 수 있다.
참고용 MetalLB installation 페이지 링크: https://metallb.universe.tf/installation/
공식 사이트에 나와있는 매니페스트 파일 방식으로 L2모드 설치를 진행 해 보았다. L2 모드는 대부분의 경우, 프로토콜 특정 구성이 필요하지 않으며, IP 주소만 필요하고 쉽게 구성 할 수 있다.
L2 모드는 워커 노드의 네트워크 인터페이스의 IP를 할당할 필요가 없다. 이 모드는 로컬 네트워크에서 ARP 요청에 직접 응답하여 클라이언트에게 기계의 MAC 주소를 제공 하는 모드다.
제일 먼저, strictARP 모드를 활성화 해야 한다.
마스터 노드에서,
kubectl edit configmap -n kube-system kube-proxy
vim editor 처럼 파일 수정이 가능 하다. 파일 속에서 41번째 줄에 있는 값을 변경 해준다.
# 기본으로 false
strictARP: true
그 후 저장 후 파일에서 나온다. MetalLB설치 할 준비는 끝났으나 이제 바로 매니페스트 파일을 적용 시켜 주면 된다
# 공식 사이트 Installation에 나온 링크
kubectl apply -f https://raw.githubusercontent.com/metallb/metallb/v0.13.10/config/manifests/metallb-native.yaml
namespace/metallb-system configured
customresourcedefinition.apiextensions.k8s.io/addresspools.metallb.io created
customresourcedefinition.apiextensions.k8s.io/bfdprofiles.metallb.io created
customresourcedefinition.apiextensions.k8s.io/bgpadvertisements.metallb.io created
customresourcedefinition.apiextensions.k8s.io/bgppeers.metallb.io created
customresourcedefinition.apiextensions.k8s.io/communities.metallb.io created
customresourcedefinition.apiextensions.k8s.io/ipaddresspools.metallb.io created
customresourcedefinition.apiextensions.k8s.io/l2advertisements.metallb.io created
serviceaccount/controller unchanged
serviceaccount/speaker unchanged
role.rbac.authorization.k8s.io/controller configured
role.rbac.authorization.k8s.io/pod-lister configured
clusterrole.rbac.authorization.k8s.io/metallb-system:controller configured
clusterrole.rbac.authorization.k8s.io/metallb-system:speaker configured
rolebinding.rbac.authorization.k8s.io/controller configured
rolebinding.rbac.authorization.k8s.io/pod-lister configured
clusterrolebinding.rbac.authorization.k8s.io/metallb-system:controller unchanged
clusterrolebinding.rbac.authorization.k8s.io/metallb-system:speaker unchanged
configmap/metallb-excludel2 created
secret/webhook-server-cert created
service/webhook-service created
deployment.apps/controller configured
daemonset.apps/speaker configured
validatingwebhookconfiguration.admissionregistration.k8s.io/metallb-webhook-configuration created이렇게 매니페스트를 적용 하게 되면 자동으로 MetalLB의 모든 필요 요소들이 자동으로 설치가 된다.
확인을 하기 위해 metallb-system namespace을 보면, controller과 speaker들이 보일 것이다
# 확인 하기 위해 새로 생성 된 metallb 네임 스페이스 리소스들 보기
kubectl get all -n metallb-system
NAME READY STATUS RESTARTS AGE
pod/controller-5fd797fbf7-r28s6 0/1 Running 0 17s
pod/controller-bdf98b979-pp7dp 1/1 Running 0 80s
pod/speaker-2hx68 1/1 Running 0 80s
pod/speaker-p2nh4 1/1 Running 0 80s
pod/speaker-r95cx 0/1 Running 0 17s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/webhook-service ClusterIP 10.233.32.213 <none> 443/TCP 17s
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
daemonset.apps/speaker 3 3 2 1 2 kubernetes.io/os=linux 80s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/controller 1/1 1 1 80s
초기 설치는 끝났으나 바로 사용 가능 하지는 않다. 사용하기 위해 먼저 초기 설정을 해 줘야 한다.
참고용 MetalLB Configuration 링크: https://metallb.universe.tf/configuration/
먼저 IP 풀을 지정 해 줘야 한다.
# IP 풀 설정을 위해 매니페스트 파일 생성
vi metallb-config.yaml
apiVersion: metallb.io/v1beta1
kind: IPAddressPool
metadata:
name: first-pool
namespace: metallb-system
spec:
addresses:
- 192.168.1.40-192.168.1.50 # IP 주소 풀 할당
---
apiVersion: metallb.io/v1beta1
kind: L2Advertisement
metadata:
name: metal
namespace: metallb-system
spec:
ipAddressPools:
- first-pool
매니페스트 파일 저장 후 적용을 한다
kubectl apply -f metallb-config.yaml
ipaddresspool.metallb.io/first-pool created
l2advertisement.metallb.io/metal created
테스팅을 위해 이미 배포 되어 있는 웹 사이트의 서비스 타입을 LoadBalancer로 바꿔 보았다
# 웹 사이트 매니페스트 파일
vi my-app.yaml
apiVersion: v1
kind: Service
metadata:
name: my-app-service
spec:
type: LoadBalancer # 전에는 NodePort로 서비스
selector:
app: my-app
ports:
- protocol: TCP
port: 80진행 중인 서비스들 목록을 확인 해보면 이젠 로드 밸런서가 EXTERNAL-IP를 지정 한 IP 풀 안에서 자동으로 부여 하는 것을 확인 할 수 있다
kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.233.0.1 <none> 443/TCP 27h
my-app-service LoadBalancer 10.233.11.219 192.168.1.40 80:30208/TCP 25m본 IP로 들어가서 확인 하면

Ingress 컨트롤러 & 리소스
인그레스는 외부 요청을 처리하는 방법을 정의하는 오브젝트다. 인그레스는 다양한 기능을 담당한다. 예를 들어, 특정 경로로 들어온 요청을 어떤 서비스로 전달할지 정의하는 라우팅 규칙, 가상 호스트를 기반으로한 요청 처리, SSL/TLS 보안 연결 처리 등을 담당한다.
NodePort나 LoadBalancer를 사용하면 위와 같은 기능을 구현할 수 있지만, NodePort의 개수가 많을 경우 각 서비스에 대해 설정을 별도로 해주어야 하는 번거로움이 있을 수 있다. 하지만 인그레스를 사용하면 한 곳에만 설정을 하면 되기 때문에 편리하다. 인그레스를 통해 요청의 경로와 처리 방식을 중앙에서 관리할 수 있어서 유연성과 효율성을 높일 수 있다. 쉽게 말하면 Ingress를 통해 특정 트래픽을 지정한 서비스 쪽으로 라우팅을 해 줄 수 있다.
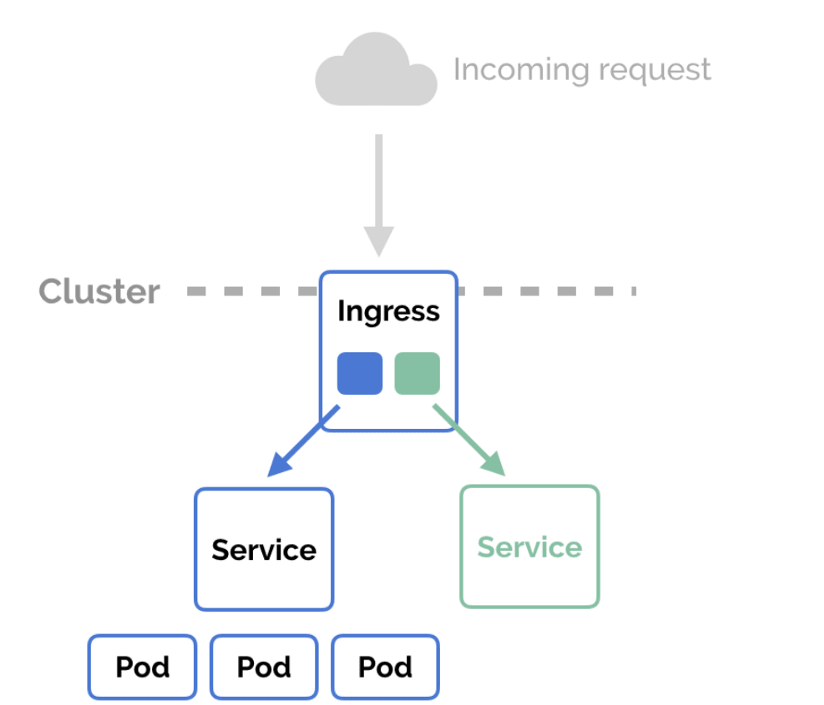
예시:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ingress-example
spec:
rules:
- host: example.com
http:
paths:
- pathType: Prefix
path: /
backend:
name: hostname-service # 목적지 서비스의 이름과 포트 번호
port: 80 여기서 host:는 해당 도메인 이름으로 접근하는 요청에 대해 처리 규칙을 적용 한다는 뜻이다. 그리고 path: 는 해당 경로의 요청을 어떤 서비스로 전달 할 것인지 정의한다.
인그레스는 요청 처리 규칙을 정의하는 선언적인 오브젝트일 뿐이며, 실제로 외부 요청을 처리하지는 않는다. 인그레스 규칙을 사용하기 위해서는 인그레스 컨트롤러라고 하는 특수한 서버에 적용해야 한다. 인그레스 컨트롤러 서버가 실제로 외부 요청을 받아들이고 인그레스 규칙을 적용한다.
인그레스 설정
클라우드 서비스를 사용하는 경우, 자사의 로드밸런서 서비스와 연동하여 인그레스를 사용할 수 있다. 그러나 자체 클라우드 구축 시에는 보통 Nginx 웹 서버 인그레스 컨트롤러를 사용 한다. 이는 쿠버네티스에서 공식적으로 개발되고 있어서 공식 깃허브 저장소에서 설치를 위한 YAML 파일을 직접 내려받을 수 있다. 그 외에도 Nginx 인그레스 컨트롤러 설치 하는 방식은 많다. Nginx Doc 사이트 참고 해서 설치 가능 하다
Nginx Documentation - Installing Nginx Ingress Controller
매니페스트 YAML 파일을 이용 하여 설치를 진행 하였다.
제일 먼저 깃 허브 쿠버네티스 인그레스 파일들을 내려 받는다
git clone https://github.com/nginxinc/kubernetes-ingress.git --branch v3.1.1
# 배포 파일들 위치로 이동
cd kubernetes-ingress/deployments이제 차례대로 아래 명령어들을 사용하여 Nginx 인그레스 컨트롤러를 배포/설치 준비를 한다
# Namespace 과 서비스 계정 생성
kubectl apply -f common/ns-and-sa.yaml
# 서비스 계정용 cluster role과 cluster role binding 생성
kubectl apply -f rbac/rbac.yaml
# Nginx 컨트롤러 설정을 위해 configMap 설정 적용
kubectl apply -f common/nginx-config.yaml
# IngressClass 리소스 생성 (없으면 Nginx 컨트롤러 실행 불가)
kubectl apply -f common/ingress-class.yaml
# 사용자 지정 리소스들 생성
kubectl apply -f common/crds/k8s.nginx.org_virtualservers.yaml
kubectl apply -f common/crds/k8s.nginx.org_virtualserverroutes.yaml
kubectl apply -f common/crds/k8s.nginx.org_transportservers.yaml
kubectl apply -f common/crds/k8s.nginx.org_policies.yaml
## 기본적으로 VirtualServer, VirtualServerRoute, TransportServer 및 Policy에 대한 사용자 지정 리소스 정의를 생성해야 한다
## 그렇지 않으면 인그레스 컨트롤러 파드가 준비 상태가 되지 않는다.
# 그 외 인그레스 컨트롤러의 TCP나 UDP 로드 밸런싱을 사용하고 싶다면
kubectl apply -f common/crds/k8s.nginx.org_globalconfigurations.yaml마지막으로 인그레스 컨트롤러 배포/설치를 진행 한다
# 기본적으로 아래 파일을 그대로 실행 하면 1 replica 인그레스 컨트롤러 파드를 생성 한다
kubectl apply -f deployment/nginx-ingress.yaml
# 마지막 단계로 loadbalancer 서비스를 통해 인그레스 컨트롤러 접근 허용을 위해
kubectl apply -f service/loadbalancer.yaml
## 선택적으로 NodePort 서비스를 통해서도 인그레스 컨트롤러 접근 가능 하다
kubectl create -f service/nodeport.yaml설치 후 결과 확인
kubectl get all -n nginx-ingress
NAME READY STATUS RESTARTS AGE
pod/nginx-ingress-bcd99bfb9-w6kn7 1/1 Running 0 152m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/nginx-ingress LoadBalancer 10.233.3.51 192.168.1.40 80:30276/TCP,443:30815/TCP 150m
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/nginx-ingress 1/1 1 1 152m
NAME DESIRED CURRENT READY AGE
replicaset.apps/nginx-ingress-bcd99bfb9 1 1 1 152m이렇게 Ingress 컨트롤러는 배포가 완료 되었다. External-IP를 통해 접속이 가능 하지만 아직 아무 서비스가 링크 되어 있지 않기 때문에 아래와 같은 화면이 보인다.

컨트롤러를 다른 서비스와 활용 하기 위해 Ingress 리소스를 생성 해야 한다.
인그레스 컨트롤러는 쿠버네티스 클러스터의 외부 트래픽을 관리하기 위한 역할을 수행 한다. 클러스터 외부에서 내부 서비스로의 트래픽 라우팅을 처리하고, 로드 밸런싱, SSL 인증서 관리 등의 기능을 제공한다.
그리고 인그레스 리소스는 인그레스 컨트롤러에 대한 구성을 정의하는 쿠버네티스 리소스이다. 인그레스 리소스는 어떤 경로로 어떤 서비스에 트래픽을 전달 할지를 정의하며, 이를 통해 클러스터 외부에서 서비스로의 트래픽을 관리할 수 있다.
테스팅을 위해 2개의 웹 사이트 서비스를 생성 하여 인그레스 리소스 설정을 통해 특정 호스트에 따라 트래픽을 전달 하겠다.
# 1번째 웹 사이트
vi my-app.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-app
spec:
replicas: 3
selector:
matchLabels:
app: my-app
template:
metadata:
labels:
app: my-app
spec:
containers:
- name: my-app
image: waji97/ecommerce:v2
ports:
- containerPort: 8000
---
apiVersion: v1
kind: Service
metadata:
name: my-app-service
spec:
type: ClusterIP
selector:
app: my-app
ports:
- protocol: TCP
port: 80
targetPort: 8000
:wq
# 2번째 웹 사이트
vi my-app2.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-app
spec:
replicas: 3
selector:
matchLabels:
app: my-app
template:
metadata:
labels:
app: my-app
spec:
containers:
- name: my-app
image: waji97/django:v2
ports:
- containerPort: 8000
---
apiVersion: v1
kind: Service
metadata:
name: my-app-service
spec:
type: ClusterIP
selector:
app: my-app
ports:
- protocol: TCP
port: 80
targetPort: 8000
:wq두 개의 서비스 및 Deployment 완료 후 확인
# 1번째 웹 사이트
vi my-app.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-app
spec:
replicas: 3
selector:
matchLabels:
app: my-app
template:
metadata:
labels:
app: my-app
spec:
containers:
- name: my-app
image: waji97/ecommerce:v2
ports:
- containerPort: 8000
---
apiVersion: v1
kind: Service
metadata:
name: my-app-service
spec:
type: ClusterIP
selector:
app: my-app
ports:
- protocol: TCP
port: 80
targetPort: 8000
:wq
# 2번째 웹 사이트
vi my-app2.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-app2
spec:
replicas: 2
selector:
matchLabels:
app: my-app2
template:
metadata:
labels:
app: my-app2
spec:
containers:
- name: my-app2
image: waji97/django:v2
ports:
- containerPort: 8000
---
apiVersion: v1
kind: Service
metadata:
name: my-app2-service
spec:
type: ClusterIP
selector:
app: my-app2
ports:
- protocol: TCP
port: 80
targetPort: 8000
:wq
# 적용 하기
kubectl apply -f my-app.yaml
deployment.apps/my-app created
service/my-app-service created
kubectl apply -f my-app2.yaml
deployment.apps/my-app2 created
service/my-app2-service created
# 현재 서비스과 Deployment들 확인 하기
NAME READY STATUS RESTARTS AGE
pod/my-app-7d7b9b8d94-92qwc 1/1 Running 0 3m48s
pod/my-app-7d7b9b8d94-xhlvd 1/1 Running 0 3m45s
pod/my-app2-764587cdfc-fc7df 1/1 Running 0 3m54s
pod/my-app2-764587cdfc-l9h85 1/1 Running 0 3m54s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes ClusterIP 10.233.0.1 <none> 443/TCP 2d
service/my-app-service ClusterIP 10.233.46.112 <none> 80/TCP 169m
service/my-app2-service ClusterIP 10.233.27.197 <none> 80/TCP 3m54s이제 Ingress 리소스를 지정 해주는 작업을 한다
# YAML 매니페스트 파일을 생성 한다
vi ingress.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: my-ingress
annotations:
kubernetes.io/ingress.class: "nginx"
kubernetes.io/ssl-redirect: "false"
spec:
rules:
- host: myapp.ingtest.com
http:
paths:
- pathType: Prefix
path: /
backend:
service:
name: my-app-service
port:
number: 80
- host: myapp2.ingtest.com
http:
paths:
- pathType: Prefix
path: /
backend:
service:
name: my-app2-service
port:
number: 80
:wq
# 위 파일을 적용
kubectl apply -f ingres.yaml
ingress.networking.k8s.io/my-ingress created
# 생성 된 리소스 확인
kubectl get ingress
NAME CLASS HOSTS ADDRESS PORTS AGE
my-ingress <none> myapp.ingtest.com,myapp2.ingtest.com 80 169m이제 두 웹 사이트가 정상 적으로 작동 하고 있는지 및 Ingress가 적용이 되었는지를 확인 하기 위해 DNS 주소들에게 접속을 한다.
접속 전에 접속 하는 PC의 'hosts' 파일에 IP주소 to DNS 주소 핑을 해 줘야 한다. 그런 이유는 보통 쿠버네티스에서 인그레스 리소스를 정의할 때, 일반적으로 클러스터 외부에서 애플리케이션에 접근하기 위해 사용할 DNS 호스트 이름을 포함한다. 그러나 기본적으로 로컬 PC의 DNS Resolver는 해당 호스트 이름과 클러스터 내의 해당 IP 주소 간의 매핑을 인식하지 못할 수 있다. 로컬 PC의 'hosts' 파일에 항목을 추가함으로써, 호스트 이름과 IP 주소 간의 수동 매핑을 생성 하면 로컬 PC에서 호스트 이름을 로컬로 해석할 수 있으며 외부 DNS 해석에 의존하지 않는다.
Window 속 'hosts' 파일 경로
C:\Windows\System32\drivers\etc\hosts
Linux 속 'hosts' 파일 경로
/etc/hosts
'hosts' 파일 속 IP 매핑 후 모습
.
.
192.168.90.73 host.docker.internal
192.168.90.73 gateway.docker.internal
# 인그레스 컨트롤러의 서비스 External-IP와 매핑
192.168.1.40 myapp.ingtest.com
192.168.1.40 myapp2.ingtest.com웹 사이트 접속 결과:
myapp.ingtest.com
myapp2.ingtest.com
//SSL 추가 및 더 디테일 한 YAML 파일 설명 그리고 /myapp /myapp2 형태의 분리 작업 남음
쿠버네티스 스토리지
볼륨과 PV 오브젝트
시크릿 리소스
컨피그맵(ConfigMap) 리소스
쿠버네티스 RBAC
네임스페이스 오브젝트
Namespace
네임스페이스는 쿠버네티스 리소스들을 논리적으로 묶어주는 오브젝트다. 패키지라고 생각하면 된다.
예시:
apiVersion: v1
kind: Namespace
metadata:
name: production위와 같이 파일을 만들거나 kubectl create ns {네임스페이스명} 으로 만들어도 된다. 쿠버네티스 사용 시 자동으로 사용하도록 설정되는 네임스페이스는 default 다. 별도로 옵션을 명시하지 않았다면 해당 네임스페이스를 사용했을 것이다.
롤 & 클러스터롤
계정 - Service Account & User Account
쿠버네티스 애플리케이션 배포
Pod 템플릿 정의하기
Pod
쿠버네티스에서는 애플리케이션을 배포할 수 있는 최소 단위인 파드(Pod)라는 개념을 제공한다. 파드는 하나 이상의 컨테이너를 포함할 수 있으며, 같은 파드 안에 있는 컨테이너는 동일한 호스트에서 실행된다.
위에서 본 예시 Yaml파일을 적용 해보면:
kubectl apply -f example-pod.yaml
pod/example-pod.yaml created이렇게 Nginx 파드가 생성 되었다. 확인 결과:
kubectl get pods
NAME READY STATUS RESTARTS AGE
example-pod 1/1 Running 0 40s이 Nginx 파드는 사용할 포트를 80으로 지정 했지만, 아직 외부에서 접근 할 수 있도록 노출 되지는 않았다.
이 파드를 삭제 하려면:
kubectl delete -f example-pod.yaml
pod "example-pod" deleted
kubectl get pods
No resources found in default namespaceDeployment 리소스 소개
쿠버네티스 클러스터 안에는 모든 리소스들을 오브젝트 형태로 관리한다. 컨테이너의 집합 (Pod), 컨테이너 집합을 관리하는 컨트롤러 (ReplicaSet), 사용자 (Service Account) 등등 을 모두 하나의 오브젝트로 사용 할 수 있다. 이 오브젝트들은 YAML 파일을 이용해서 생성 할 수 있다. 이 YAML 파일들을 Manifest(매니페스트) 파일이라고 부른다. 이 파일은 일련의 설정 정보를 포함하고 있으며, 쿠버네티스 클러스터에게 어떤 리소스를 생성하고 구성해야 하는지를 지시한다. 매니페스트 파일의 예시:
# Nginx 컨테이너로 구성된 파드를 직접 생성하는 yaml 파일 예시
apiVersion: v1
kind: Pod
metadata:
name: example-pod
spec:
containers:
- name: example-container
image: nginx:latest
ports:
- containerPort: 80
protocol: TCP쿠버네티스 매니페스트 YAML파일은 일반적으로 apiVersion, kind, metadata, spec 네 가지 항목으로 구성 된다.
- apiVersion yaml 파일에서 정의한 오브젝트의 API 버전
- kind 리소스의 종류(
kubectl api-resources명령어의 KIND 항목에서 확인 가능) - metadata 리소스의 부가 정보(label, annotation, name 등)
- spec 리소스를 생성하기 위한 자세한 정보(파드에서 실행될 컨테이너 정보, 도커 이미지 정보, 포트 정보 등).
-은 list 형식이라고 생각하면 된다.example-container라는 이름의nginx:latest이미지를 가진 컨테이너가 있다는 뜻이고, 포트는 80을 사용한다는 뜻이다.
kubectl apply -f <yaml 파일 이름> 명령어를 통해 쿠버네티스에 파드를 생성할 수 있다.
kubectl은 이러한 매니페스트 파일을 사용하여 쿠버네티스 클러스터를 관리하기 위한 커맨드 라인 도구이다. 개발자나 시스템 관리자는 kubectl을 활용하여 매니페스트 파일을 통해 Kubernetes 클러스터 내의 리소스를 생성, 조회, 수정, 삭제할 수 있다.
kubectl은 다양한 기능과 옵션을 제공한다. 일반적으로 다음과 같은 작업을 수행할 수 있다:
-
클러스터와의 연결: kubectl을 사용하여 Kubernetes 클러스터와 통신하고, 사용자 인증 및 인가를 설정한다.
-
리소스 관리: kubectl을 통해 파드, 서비스, 디플로이먼트 등의 리소스를 생성, 조회, 수정, 삭제할 수 있습니다. 또한, 클러스터 내의 다양한 리소스들의 상태를 확인할 수 있다.
-
로그 및 이벤트 확인: kubectl을 사용하여 파드의 로그를 확인하거나 클러스터의 이벤트를 조회할 수 있다. 이를 통해 애플리케이션의 동작 상태를 추적하고 디버깅할 수 있다.
-
스케일링 및 롤링 업데이트: kubectl을 사용하여 애플리케이션을 스케일 업/다운하거나, 롤링 업데이트를 수행할 수 있다. 이를 통해 애플리케이션의 확장성과 가용성을 관리할 수 있다.
Deployment
실제 쿠버네티스 환경에서 사용하는 오브젝트다. 디플로이먼트를 생성하면 이에 대응하는 레플리카셋도 함께 생성된다.
예시:
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-nginx-deployment
spec:
replicas: 3
selector:
matchLabels:
app: my-nginx
template:
metadata:
name: my-nginx-pod
labels:
app: my-nginx
spec:
containers:
- name: nginx
image: nginx:1.10
ports:
- containerPort: 80레플리카셋을 정의한 Yaml 파일과 비교해서 kind 밖에 바뀐 것이 없다. 디플로이먼트를 사용하는 핵심적인 이유는 애플리케이션의 업데이트와 배포를 편하게 하기 위해서이다. 새로운 별도의 레플리카셋이 생성되고 변경된 버전의 팟을 생성해 새로운 레플리카셋에 넣고 기존의 레플리카셋에 들어있는 팟의 수를 줄인다. 숫자로 나타내면 다음과 같다.
기존 레플리카셋 팟 숫자 - 새로운 레플리카셋의 팟 숫자. 3 - 0, 3 - 1, 2 - 2, 1 - 3, 0 - 3
kubectl describe deployment {deployment name} 의 명령어를 통해 내부적으로 어떤 이벤트들이 진행되었는지 확인할 수 있다.그리고 이러한 버전 변경에 대한 정보를 보관하고 있어 쉽게 롤백이 가능하다.kubectl rollout history deployment {deployment name} 버전 정보 조회kubectl rollout undo deployment {deployment name} --to -revision={버전 숫자} 해당 버전으로 변경
ReplicaSet 리소스 소개
ReplicaSet
Pod의 수를 관리하고, 원하는 수의 Pod가 항상 실행되도록 유지하는 역할을 하는 오브젝트. ReplicaSet은 주로 Pod을 생성하고, 감시하고, Pod가 정상적으로 실행되지 않을 경우 다른 Pod으로 대체하는 작업을 수행한다. 레플리카셋은 정해진 수의 동일한 팟이 항상 실행되도록 관리해준다.
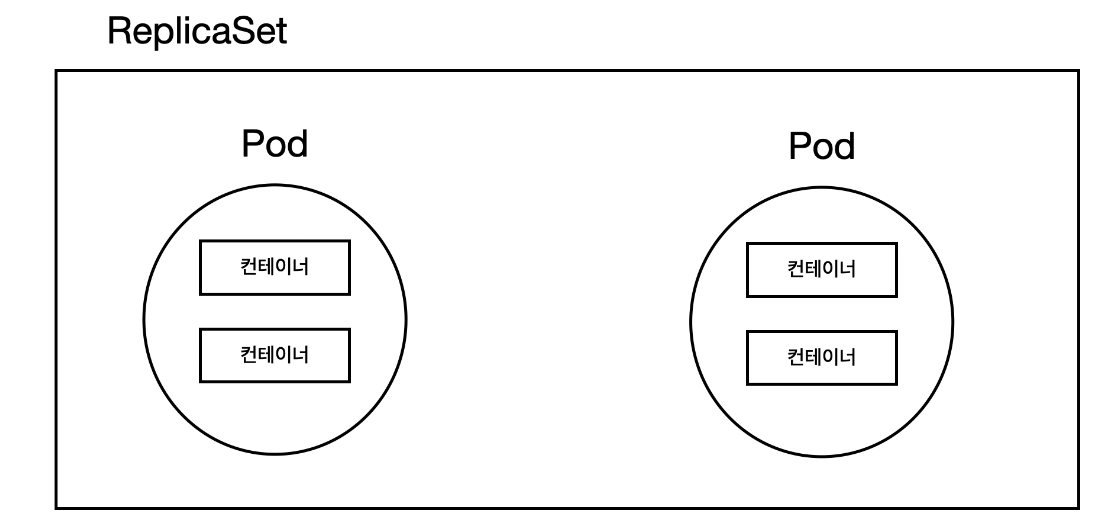
예시:
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: replicaset-nginx
spec:
replicas: 3
selector:
matchLabels:
app: my-nginx-pods-label # 여기까지가 레플리카셋의 정의다.
template: # 여기서부터가 포드의 정의다.
metadata:
name: my-nginx-pod
labels:
app: my-nginx-pods-label
spec:
containers:
- name: nginx
image: nginx:latest
ports:
- containerPort: 80위 YAML파일 속 7번 줄부터는 ReplicaSet의 정의다. replicas: 3는 동일한 파드를 몇 개 유지시킬 것인지에 대한 정보다. template는 ReplicaSet에서 어떤 파드를 생성 할 것인지에 대한 정보다. 10번 줄에 있는 matchLabels는 기존에 동일한 이름의 파드가 존재 한다면 파드를 관리하여 replicas:에 정의 되어있는 숫자 만큼 파드들을 생성 또는 제거 한다. 한마디로 matchLabels는 특정 레이블 지정하는 필드라고 생각 하면 된다. 레플리카셋은 일정 개수의 팟을 유지하는 것을 목적으로 두고 있다
StatefulSet 리소스 소개
DaemonSet 리소스 소개
HPA(Horizontal Pod Autoscaler) 리소스 소개
Job & CronJob 리소스 소개
쿠버네티스 클러스터 관리
클러스터 생성 및 설정 (Kubeadm)
본질적으로 "Vanilla Kubernetes"는 광범위한 사용 사례에 적합한 쿠버네티스의 표준 버전을 의미하다. 이 버전은 쿠버네티스의 핵심 기능들을 모두 포함하고, 이번 데모에서는 한 물리 서버에, 가상 머신 3대를 사용하여 쿠버네티스 클러스터를 생성할 예정이다.
💡 현재 VMWare Workstation에서 실습 진행
- Master Node: 192.168.1.10
- Worker Node 1: 192.168.1.20
- Worker Node 2: 192.168.1.30
쿠버네티스 클러스터 설정 시 Swap Memory 비활성화를 권장 한다. Swap Memory는 하드 디스크를 이용하여 RAM을 보충하는 가상 메모리이지만, K8s는 많은 자원을 요구하므로 Swap Memory를 사용하면 성능 저하와 스케줄링 지연이 발생할 수 있다. 또한, Swap Memory는 리소스 관리에 문제를 야기할 수 있으므로 안정적이고 효율적인 성능을 위해 스왑 메모리를 비활성화해야 한다. 더 자세한 내용은 여기 블로그 링크 참고.
CentOS 7에서 K8s 클러스터
Docker Installation
시작 전, 이전 버전들을 삭제 한다
sudo dnf remove docker \
docker-client \
docker-client-latest \
docker-common \
docker-latest \
docker-latest-logrotate \
docker-logrotate \
docker-engineyum-utils 설치와 로컬 yum repository (저장소) 지정
sudo dnf install -y yum-utilssudo dnf-config-manager \
--add-repo \
https://download.docker.com/linux/centos/docker-ce.repo도커 최신 버전 설치
sudo dnf install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin도커 서비스 시작
sudo systemctl start docker도커 버전 확인
docker versionKubernetes Installation
💡 Master Node과 Worker Node에서 동일 하게 작업
Swap Memory 비활성화
swapoff -adaemon.json 파일 생성 후 cgroupdriver을 systemd로 설정
vi /etc/docker/daemon.json
{
"exec-opts": ["native.cgroupdriver=systemd"]
}daemon 재시작
systemctl daemon-reload
systemctl restart docker쿠버네티스 로컬 저장소 지정 및 설치
vi /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://packages.cloud.google.com/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=https://packages.cloud.google.com/yum/doc/yum-key.gpg
https://packages.cloud.google.com/yum/doc/rpm-package-key.gpg
# 쿠버네티스 설치
dnf install -y kubelet-1.19.16-0.x86_64 kubectl-1.19.16-0.x86_64 kubeadm-1.19.16-0.x86_64쿠버네티스 설치 완료 확인
rpm -qa | grep kube쿠버네티스 클러스터 요소들 통신을 위해 방화벽 포트 추가
firewall-cmd --permanent --add-port=80/tcp
firewall-cmd --permanent --add-port=443/tcp
firewall-cmd --permanent --add-port=2376/tcp
firewall-cmd --permanent --add-port=2379/tcp
firewall-cmd --permanent --add-port=2380/tcp
firewall-cmd --permanent --add-port=6443/tcp
firewall-cmd --permanent --add-port=8472/udp
firewall-cmd --permanent --add-port=9099/tcp
firewall-cmd --permanent --add-port=10250/tcp
firewall-cmd --permanent --add-port=10251/tcp
firewall-cmd --permanent --add-port=10252/tcp
firewall-cmd --permanent --add-port=10254/tcp
firewall-cmd --permanent --add-port=10255/tcp
firewall-cmd --permanent --add-port=30000-32767/tcp
firewall-cmd --permanent --add-port=30000-32767/udp
firewall-cmd --permanent --add-masquerade
firewall-cmd --reload💡마스터 노드에서만 진행
쿠버네티스 클러스터 생성
kubeadm init --apiserver-advertise-address=192.168.1.10 --pod-network-cidr=10.244.0.0/16
# K8s control plane 생성 완료 화면
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.1.10:6443 --token 172vji.r0u77jcmcnccm6no \
--discovery-token-ca-cert-hash sha256:72b9648c647f724ab52471847cb06c47b23097375f2e67633b745fc69db16e8d kubectl 활성화 위해 admin.conf 복사 작업
mkdir -p $HOME/.kube
cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
chown $(id -u):$(id -g) $HOME/.kube/config네트워크 플러그인 다운로드 (Flannel)
[ CNI(Container Network Interface)는 컨테이너를 위한 네트워킹을 제어할 수 있는 플러그인을 만들기 위한 표준이라고 한다. 간단하게 설명 하면 CNI플러그인을 쿠버네티스 클러스터에 설치하여 서로 다른 노드에서 실행되는 컨테이너 간의 네트워킹을 할 수 있다 ]
더 자세한 내용은 링크 참고
curl -O -L https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.ymlkube-flannel.yml 파일 안에 --iface=(가상 인터페이스 이름) 지정
vi kube-flannel.yml
args:
- --ip-masq
- --kube-subnet-mgr
- --iface=ens160네트워크 플러그인 YAML 파일 적용 후 kubelet 재시작
kubectl apply -f kube-flannel.yml
systemctl restart kubelet💡 Worker Node에서 작업
Master Node에서 받은 Discovery Token 값을 join 명령어로 통해 Master과 Worker 노드 묶기
kubeadm join 192.168.1.10:6443 --token 172vji.r0u77jcmcnccm6no \
--discovery-token-ca-cert-hash sha256:72b9648c647f724ab52471847cb06c47b23097375f2e67633b745fc69db16e8d
This node has joined the cluster:
* Certificate signing request was sent to apiserver and a response was received.
* The Kubelet was informed of the new secure connection details.
Run 'kubectl get nodes' on the control-plane to see this node join the cluster.Join 작업이 완료 후 마스터 노드에서 쿠버네티스 클러스터 확인
kubectl get nodes
NAME STATUS ROLES AGE VERSION
master Ready master 107m v1.19.16
node-1 Ready <none> 91s v1.19.16
node-2 Ready <none> 48s v1.19.16Rocky Linux 9.1에서 K8s 클러스터
Docker Installation
업데이트 확인 및 업데이트 있으면 실행
sudo dnf check-update
sudo dnf update도커 repository (저장소) 추가
sudo dnf config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo도커 설치
sudo dnf install docker-ce docker-ce-cli containerd.io도커 시작 및 확인
sudo systemctl start docker
sudo systemctl enable docker
sudo docker version'sudo' 생략 하고 docker 만 쓰고 싶으면
sudo usermod -aG docker $(whoami)Kubernetes Installation
💡 Master Node과 Worker Node에서 동일 하게 작업
Swap Memory 비활성화
sudo swapoff -adaemon.json 파일 생성 후 cgroupdriver을 systemd로 설정
sudo vi /etc/docker/daemon.json
{
"exec-opts": ["native.cgroupdriver=systemd"]
}daemon 재시작
sudo systemctl daemon-reload
sudo systemctl restart docker쿠버네티스 로컬 저장소 지정 및 설치
sudo vi /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://packages.cloud.google.com/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=https://packages.cloud.google.com/yum/doc/yum-key.gpg
https://packages.cloud.google.com/yum/doc/rpm-package-key.gpg
# 쿠버네티스 설치
sudo dnf -y kubelet-1.19.16-0.x86_64 kubectl-1.19.16-0.x86_64 kubeadm-1.19.16-0.x86_64쿠버네티스 설치 완료 확인
sudo rpm -qa | grep kube쿠버네티스 클러스터 요소들 통신을 위해 방화벽 포트 추가
sudo firewall-cmd --permanent --add-port=80/tcp
sudo firewall-cmd --permanent --add-port=443/tcp
sudo firewall-cmd --permanent --add-port=2376/tcp
sudo firewall-cmd --permanent --add-port=2379/tcp
sudo firewall-cmd --permanent --add-port=2380/tcp
sudo firewall-cmd --permanent --add-port=6443/tcp
sudo firewall-cmd --permanent --add-port=8472/udp
sudo firewall-cmd --permanent --add-port=9099/tcp
sudo firewall-cmd --permanent --add-port=10250/tcp
sudo firewall-cmd --permanent --add-port=10251/tcp
sudo firewall-cmd --permanent --add-port=10252/tcp
sudo firewall-cmd --permanent --add-port=10254/tcp
sudo firewall-cmd --permanent --add-port=10255/tcp
sudo firewall-cmd --permanent --add-port=30000-32767/tcp
sudo firewall-cmd --permanent --add-port=30000-32767/udp
sudo firewall-cmd --permanent --add-masquerade
sudo firewall-cmd --reload💡마스터 노드에서만 진행
슈퍼 유저 (root 계정)으로 전환
sudo su쿠버네티스 클러스터 생성
kubeadm init --apiserver-advertise-address=192.168.1.10 --pod-network-cidr=10.244.0.0/16
# K8s control plane 생성 완료 화면
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
sudo kubeadm join 192.168.1.10:6443 --token 1x7qb2.dww3u7mjsrq2hoxt --discovery-token-ca-cert-hash sha256:10a6803e9a45bb029af4ad3c1d0d894dfaee9980d2318c495739296daeffb9ebkubectl 활성화를 위해 admin.conf 복사 작업 (꼭 root계정으로 해야됨!)
mkdir -p $HOME/.kube
cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
chown $(id -u):$(id -g) $HOME/.kube/config네트워크 플러그인 다운로드
curl -O -L https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml네트워크 플러그인 YAML 파일 적용 후 kubelet 재시작 (꼭 root계정으로 해야됨!)
kubectl apply -f kube-flannel.yml
systemctl restart kubelet💡 Worker Node에서 작업
Master Node에서 받은 Discovery Token 값을 join 명령어로 통해 Master과 Worker 노드 묶기
sudo kubeadm join 192.168.1.10:6443 --token 1x7qb2.dww3u7mjsrq2hoxt \
--discovery-token-ca-cert-hash sha256:10a6803e9a45bb029af4ad3c1d0d894dfaee9980d2318c495739296daeffb9eb
This node has joined the cluster:
* Certificate signing request was sent to apiserver and a response was received.
* The Kubelet was informed of the new secure connection details.
Run 'kubectl get nodes' on the control-plane to see this node join the cluster.Join 작업이 완료 후 마스터 노드에서 쿠버네티스 클러스터 확인
sudo kubectl get nodes
NAME STATUS ROLES AGE VERSION
master Ready master 33m v1.19.16
worker-1 Ready <none> 91s v1.19.16
worker-2 Ready <none> 48s v1.19.16Ubuntu 20.04.6에서 K8s 클러스터
Docker Installation
업데이트 확인 및 실행
sudo apt update필수 패키지 설치
sudo apt install ca-certificates curl gnupg lsb-release도커 GPG 키 추가
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg도커 Repository 등록
echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://download.docker.com/linux/ubuntu \
$(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null도커 엔진 설치 및 확인
sudo apt update
sudo apt install docker-ce docker-ce-cli containerd.io
sudo docker version
sudo systemctl status docker
## 서버 재시작 시 docker 가 자동으로 시작되도록 설정 ##
sudo systemctl enable dockerKubernetes Installation
💡 Master Node과 Worker Node에서 동일 하게 작업
Swap Memory 비활성화
sudo swapoff -a노드간 통신을 위한 iptables에 브릿지 관련 설정 추가
sudo vi /etc/modules-load.d/k8s.conf
br_netfilter
sudo vi /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
# sysctl.conf 파일 맨 아래에도 동일 하게 두 줄 추가
sudo vi /etc/sysctl.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
# sysctl 설정 파일들의 변동을 저장 하기 위해
sudo sysctl --system
sudo sysctl -pdaemon.json 파일 생성 후 cgroupdriver을 systemd로 설정
sudo vi /etc/docker/daemon.json
{
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
},
"storage-driver": "overlay2"
}daemon 재시작
sudo systemctl daemon-reload
sudo systemctl restart docker
sudo systemctl enable dockerapt 업데이트 및 ca 관련 패키지 다운로드 및 설
sudo apt update
sudo apt install -y apt-transport-https ca-certificates curl
sudo curl -fsSLo /usr/share/keyrings/kubernetes-archive-keyring.gpg https://packages.cloud.google.com/apt/doc/apt-key.gpg도커 gpg 및 소스 리스트 내용 추가 및 apt 업데이
echo "deb [signed-by=/usr/share/keyrings/kubernetes-archive-keyring.gpg] https://apt.kubernetes.io/ kubernetes-xenial main" | sudo tee /etc/apt/sources.list.d/kubernetes.list
sudo apt updatekubeadm, kubelet 그리고 kubectl 설치 및 활성화
sudo apt install -y kubelet kubeadm kubectl
sudo apt-mark hold kubelet kubeadm kubectl
sudo systemctl start kubelet && systemctl enable kubelet💡마스터 노드에서만 진행
쿠버네티스 클러스터 생성을 위해 kubeadm init 실행
sudo kubeadm init --apiserver-advertise-address=192.168.1.10 --pod-network-cidr=10.244.0.0/16
# K8s control plane 생성 완료 화면
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.1.10:6443 --token mu72kx.sn06xzcg3lde7mha \
--discovery-token-ca-cert-hash sha256:d134654458b474c796667776ab8175adbc0e1dc4bc21a712a19a7bb405ee9273 kubectl 활성화를 위해 admin.conf 복사 작업
sudo mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config네트워크 플러그인 다운로드
curl -O -L https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml네트워크 플러그인 YAML 파일 적용 후 kubelet 재시작
kubectl apply -f kube-flannel.yml
sudo systemctl restart kubelet💡 Worker Node에서 진행
Master Node에서 받은 Discovery Token 값을 join 명령어로 통해 Master과 Worker 노드 묶기
sudo kubeadm join 192.168.1.10:6443 --token mu72kx.sn06xzcg3lde7mha \
--discovery-token-ca-cert-hash sha256:d134654458b474c796667776ab8175adbc0e1dc4bc21a712a19a7bb405ee9273
This node has joined the cluster:
* Certificate signing request was sent to apiserver and a response was received.
* The Kubelet was informed of the new secure connection details.
Run 'kubectl get nodes' on the control-plane to see this node join the cluster.Join 작업이 완료 후 마스터 노드에서 쿠버네티스 클러스터 확인
kubectl get nodes
NAME STATUS ROLES AGE VERSION
master Ready master 33m v1.19.16
worker-1 Ready <none> 91s v1.19.16
worker-2 Ready <none> 48s v1.19.16Error Troubleshooting
[ERROR CRI]: container runtime is not running [Issue Encountered]
이 문제는 사용되는 CRI가 Containerd인 경우 마스터 노드에서 kubeadm init 명령을 실행할 때 자주 발생한다. 대부분의 경우 config.toml 파일에 문제가 있다.
해결
# config.toml 파일을 삭제 한다
sudo rm /etc/containerd/config.toml
# containerd 서비스 재시작
sudo systemctl restart containerdThe connection to the server <IP 주소>:6443 was refused - did you specify the right host or port?
이 에러는 보통 API 서버가 실행 중이지 않거나 네트워킹 문제가 있는 경우 발생할 수 있다. 하지만 이 애러가 마스터 노드 재시작 후 발생 한다면 Swap 메모리 문제일 가능성이 높다. 그런 경우 리소스 제약 때문에 발생한 문제일 가능성이 있다. Swap이 활성화되어 있으면, 커널은 비활성화된 페이지를 디스크로 이동시킬 수 있으며, 이로 인해 API 요청과 같은 지연이 발생할 수 있다. 이러한 시스템 재시작 할때 매번 swap memory를 비활성화 해야 된다.
해결
/etc/fstab 설정 파일안에서 swap을 주석 처리 해준다
sudo vi /etc/fstab
# /etc/fstab: static file system information.
#
# Use 'blkid' to print the universally unique identifier for a
# device; this may be used with UUID= as a more robust way to name devices
# that works even if disks are added and removed. See fstab(5).
#
# <file system> <mount point> <type> <options> <dump> <pass>
# / was on /dev/sda3 during curtin installation
/dev/disk/by-uuid/05bb7e29-bd2d-4ffb-86c6-8868e48548f4 / ext4 defaults 0 1
# /boot/efi was on /dev/sda2 during curtin installation
/dev/disk/by-uuid/ebbd40d6-5f57-4214-806f-8cf8e929b23d /boot/efi ext4 defaults 0 1
# /swap.img none swap sw 0 0클러스터 생성 및 설정 (Kubespray)
이번 데모에서는 한 물리 서버에, 가상 머신 4대를 사용하여 쿠버네티스 클러스터를 생성할 예정이다.
💡 현재 VMWare Workstation에서 실습 진행
- Control Node (Ubuntu 22.04): 192.168.1.90
- Master Node (CentOS 7): 192.168.1.150
- Worker Node 1 (CentOS 7): 192.168.1.160
- Worker Node 2 (CentOS 7): 192.168.1.170
Kubespray를 통해 클러스터 생성
Kubespray는 쿠버네티스 클러스터를 배포하고 관리하기 위한 오픈 소스 도구이다. Ansible을 기반으로 하며, 클러스터 설정, 노드 배치, 네트워킹, 보안 설정 등을 자동화 한다. 이를 통해 사용자는 일관된 방식으로 쿠버네티스 클러스터를 배포하고 관리할 수 있으며, 다양한 환경에서 유연하게 사용할 수 있다. 간단하게 생각하면 Kubespray는 K8s를 설치 할 수 있는 Ansible 묶음이다. 중요한 키 포인트들은:
- AWS, GCE, Azure, OpenStack 또는 Baremetal등에서 쉽게 배포 할 수 있다
- 고가용성 클러스터를 생성 할 수 있다
- 네트워크 플러그인의 선택 가능 하다
- 대부분의 인기 있는 리눅스 배포판을 지원 한다
- 지속적인 통합 테스트를 지원 한다
기존에는 Kargo라는 이름이었다. 더 많은 정보는 Kubespray 깃 허브 페이지를 참고 할 수 있다.
Requirements & Prerequisites
- 최소 쿠버네티스 설치 버전은 v1.24
- Python3.9+, Ansible v2.11+, Jinja 2.11+ 그리고 python-netaddr이 Ansible 명령어를 실행 할 노드에 설치 되어 있어야 된다
- 도커 이미지를 가져오기 위해 대상 서버는 인터넷에 액세스해야 한다. (오프라인 환경은 여기 참조)
- 대상 서버들은 IPv4 Forwarding을 허용하도록 설정되어 있어야 한다
- 방화벽은 관리되지 않으므로, 배포 전에 방화벽을 비활성화 하도록 해야 한다.
- kubespray를 root 사용자 계정이 아닌 다른 사용자 계정에서 실행하는 경우, 올바른 권한 상승 방법을 대상 서버에 구성해야 한다. 그런 다음
ansible_become플래그 또는 명령 매개변수--become또는-b를 지정해야 합니다. - Master & Worker Nodes 최소 사양 1500MB RAM, 2CPU, 20GB 디스크 공간
- Ansible Node (Control Node) 최소 사양 1024MB RAM, 1CPU, 20GB 디스크 공간
- 모든 노드 들은 인터넷 통신이 가능 해야 된다
- 각 노드의 계정 들은 관리자 권한(sudo) 명령어를 사용 할 수 있어야 된다
💡중요 포인트들!
Ansible은 오픈 소스 IT 자동화 도구로, 서버 설정, 배포, 관리 작업을 간편하게 자동화하는 데 사용 된다. 파이썬으로 작성 되었으며, SSH를 통해 에이전트 없이 호스트를 제어 한다.
Jinja는 파이썬 기반의 템플릿 엔진으로, 동적으로 데이터를 조작하여 텍스트를 생성하는 데 사용 된다. Jinja는 Ansible과 함께 사용되며, 템플릿 파일과 변수를 결합하여 구성 파일을 생성하거나 동적으로 콘텐츠를 생성하는 데 유용 하다.
Ansible과 Jinja를 Control 노드에 설치 하겠다. 이 노드는 클러스터를 배포하는 역할 만 수행하고 실제 클러스터에는 구성 되지 않는다.
그리고 진행 하기 전, selinux 상태도 확인 해야 한다.
# 파일 안에 selinux=enforcing값을 selinux=disabled로 변경
vi /etc/selinux/config
.
.
selinux=disabledKubespray 실행 하기
Control 노드 에서 작업
전체 패키지 업데이트 및 파이썬 그리고 pip을 설치 한다
sudo apt update
# 깃을 사용 하여 kubespray 코드를 가져와야 한다
sudo apt install git python3 python3-pip -y파이썬 버전과 pip 버전을 확인 한다
python3 -V
python 3.10.6
pip -V
pip 22.0.2 from /usr/lib/python3/dist-packages/pip (python 3.10)pip을 통해 Ansible 과 Jinja 패키지를 설치 할 수 있다. pip을 통해 설치하는 것이 권장되는 이유는 pip가 파이썬의 패키지 설치 도구이며, Ansible과 Jinja 모두 파이썬 기반 도구이기 때문이다
git clone 명령어를 통해 kubespray 깃 허브 소스 코드를 내려 받는다
git clone https://github.com/kubernetes-incubator/kubespray.gitkubespray의 깃 허브 소스 코드를 내려 받으면 이미 필요한 요소들을 쉽게 설치 할 수 있는 requirements.txt 파일이 존재 한다
# kubespray 디렉터로 이동
cd kubespray
# 파일 안에 있는 모든 항목들을 pip을 사용 하여 설치 한다
pip install -r requirements.txt참고로 requirements.txt 파일 안에 존재하는 항목들은
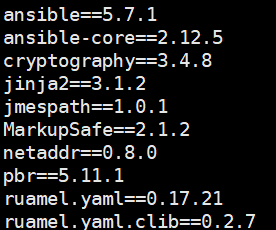
설치가 무사히 완료 된 후 아래 명렁어를 사용 했을때 ansible 버전을 확인 할 수 있다
ansible --version
ansible [core 2.12.5]
config file = /home/ansible/kubespray/ansible.cfg
configured module search path = ['/home/ansible/kubespray/library']
ansible python module location = /home/ansible/.local/lib/python3.10/site-packages/ansible
ansible collection location = /home/ansible/.ansible/collections:/usr/share/ansible/collections
executable location = /home/ansible/.local/bin/ansible
python version = 3.10.6 (main, Mar 10 2023, 10:55:28) [GCC 11.3.0]
jinja version = 3.1.2
libyaml = True-bash: ansible: command not found?
만약에 설치가 완료 되었지만 ansible 명령어를 찾을 수 없다고 나온다면, Ansible이 설치된 디렉터리가 PATH 환경 변수에 포함되지 않았다는 거다.
Ansible 설치 경로는 여기서 확인
ls ~/.local/bin/
__pycache__ ansible-config ansible-console ansible-galaxy ansible-playbook ansible-test jp.py pbr
ansible ansible-connection ansible-doc ansible-inventory ansible-pull ansible-vault netaddrpip을 사용하여 Ansible을 설치하면 기본적으로 ~/.local/bin 디렉토리에 설치 된다. Python packaging의 일반적인 관례로, 사용자 별로 패키지를 격리하고 개별적으로 관리하기 위해 사용자의 로컬 디렉토리에 설치되는 것이다
Ansible의 설치 경로를 ~/.bashrc파일에 추가 해주면 해결 된다
~/.bashrc는 Bash Shell 환경을 자신의 선호에 맞게 구성할 수 있는 파일
vi ~/.bashrc
# 마지막 줄에 추가
export PATH=$PATH:/home/ansible/.local/bin
# 저장 후 나가기
:wq
# bashrc파일의 변경 내용을 업데이트
source ~/.bashrcansible이 정상적으로 작동 하는지 확인 후 호스트 파일을 만들기 위해 아래 명령어들을 실행 한다
# inventory/sample 디렉토리의 내용을 inventory/mycluster 디렉토리로 복사한다
# -rfp 옵션을 사용하여 재귀적으로 모든 하위 디렉터리 포함 복사하여 원본 파일의 속성들도 보존 한다
cp -rfp inventory/sample inventory/mycluster
# IPS라는 배열 변수를 선언하고, IP 주소 목록을 할당한다
declare -a IPS=(192.168.1.150 192.168.1.160 192.168.1.170)
# inventory.py라는 파이썬 스크립트를 실행한다
# 스크립트는 CONFIG_FILE 환경 변수가 설정되어야 하므로, hosts.yaml로 설정 한다
CONFIG_FILE=inventory/mycluster/hosts.yml python3 contrib/inventory_builder/inventory.py ${IPS[@]}
# inventory 디렉토리의 주어진 IP 주소와 디렉토리 구조를 사용하여 인벤토리 파일(hosts.yaml)을 생성하는 설정 프로세스설정 완료 후 hosts.yaml 파일안에 내용을 아래와 같이 수정 한다
vi inventory/mycluster/hosts.yml
all:
hosts:
node1:
ansible_host: 192.168.1.150 # 작업을 실행하기 위해 대상 노드에 연결할 때 사용하는 IP 주소 또는 호스트 이름을 지정하는 필드
ip: 192.168.1.150
access_ip: 192.168.1.150
node2:
ansible_host: 192.168.1.160
ip: 192.168.1.160
access_ip: 192.168.1.160
node3:
ansible_host: 192.168.1.170
ip: 192.168.1.170
access_ip: 192.168.1.170
children:
kube_control_plane: # 마스터 노드 지정 하는 곳
hosts:
node1:
kube_node: # 워커 노드 지정 하는 곳
hosts:
node2:
node3:
etcd: # etcd 노드 지정 하는 곳
hosts:
node1:
k8s_cluster:
children:
kube_control_plane:
kube_node:
calico_rr:
hosts: {}그 외 쿠버네티스 클러스터 관련 검토 및 수정 할 수 있는 설정 파일은:
vi inventory/mycluster/group_vars/k8s_cluster/k8s-cluster.yml
# 파일 내용이 너무 길어서 중요한 요소들만 지정 하였다
# 20번째 줄
kube_version: v1.26.5
# 70번째 줄
kube_network_plugin: calico
# 76번째 줄
kube_service_addresses: 10.233.0.0/18
# 81번째 줄
kube_pods_subnet: 10.233.64.0/18
# 160번째 줄
cluster_name: cluster.local
# 229번째 줄
container_manager: containerd마지막으로 추가적인 클러스터 요소들을 클러스터 설치 시 같이 활성화 시킬 수 있게 설정 할 수 있는 파일:
vi inventory/mycluster/group_vars/k8s_cluster/addons.yml
# 파일 내용이 너무 길어서 중요한 요소들만 지정 하였다
# 4번째 줄
dashboard_enabled: false
# 7번째 줄
helm_enabled: false
# 10번째 줄
registry_enabled: false
# 16번째 줄
metrics_server_enabled: false
# 100번째 줄
ingress_nginx_enabled: false
# 177번째 줄
metallb_enabled: false
# 246번째 줄
argocd_enabled: false만약에 Control 노드에서 root 유저로 지금 까지 진행 하였다면 아래 호스트 노드들에서의 작업이 불필요하다
호스트 노드들에서 작업
현재 까지의 Control노드의 설정들은 'ansible'유저 이름로 진행 되었다. 그렇기 때문에 Ansible 명령어를 실행 하려면 호스트 노드들도 동일한 이름의 유저가 존재 해야 한다. 각각 호스트 노드에 먼저 새로운 'ansible' 유저 생성 후 sudoers.d 파일에 등록 시켜 줘야 한다.
# 모든 호스트노드에서 동일하게 설정
useradd ansible
passwd ansible
New Password:
# root 사용자를 위해 sudoers파일에 ansible 사용자가 비밀번호를 입력 하지 않고도 root 권한으로 모든 명령어를 실행할 수 있게 해 준다
echo "ansible ALL=(ALL) NOPASSWD:ALL" | sudo tee /etc/sudoers.d/rootControl노드에서 작업
이제 Control 노드가 호스트 노드들 (마스터 와 워커 노드)의 설정들을 자유롭게 할 수 있게 접근권한을 부여 하는 설정을 해야 한다
첫째로 Control노드에서 SSH 접속을 위해 SSH 키를 발행 한다
ssh-keygenSSH키를 발급 받은 후 그 Public키를 모든 호스트 노드들에게 전달 해야된다.
# non-root 유저(ansible 유저)로 진행 하였을 경우
ssh-copy-id ansible@192.168.1.150
ssh-copy-id ansible@192.168.1.160
ssh-copy-id ansible@192.168.1.170
# root 유저로 진행 하였을 경우
ssh-copy-id root@192.168.1.150
ssh-copy-id root@192.168.1.160
ssh-copy-id root@192.168.1.170마지막으로 Kubespray 실행 하기 전에 Firewall을 비활성화 그리고 IPv4 포워딩을 활성화 해주는 작업을 진행 한다.
쿠버네티스는 클러스터의 구성요소간 통신에 다양한 네트워크 포트를 사용 한다. 방화벽을 사용하지 않도록 설정하면 클러스터 노드 간의 원활한 통신을 위해 필요한 포트가 열려 있고 차단되지 않도록 할 수 있다. 그리고 IPv4 Forwarding을 사용 하면 쿠버네티스 클러스터에서는 노드, 포드 및 서비스간 서로 다른 네트워크 인터페이스 또는 서브넷 간에 네트워크 트래픽을 라우팅할 수 있다.
# Kubespray 디렉토리로 이동
cd kubespray
# ansible 명령어를 통해 모든 호스트들의 firewalld 서비스 중단
ansible all -i inventory/mycluster/hosts.yml -m shell -a "sudo systemctl stop firewalld && sudo systemctl disable firewalld"
# IPv4 포트 forwarding 기능 활성화
ansible all -i inventory/mycluster/hosts.yml -m shell -a "echo 'net.ipv4.ip_forward=1' | sudo tee -a /etc/sysctl.conf"
# Swap memory off 설정
ansible all -i inventory/mycluster/hosts.yml -m shell -a "sudo sed -i '/ swap / s/^\(.*\)$/#\1/g' /etc/fstab && sudo swapoff -a"모든 준비 단계들과 요소들이 끝났다. 이제 Kubespray를 통해 Kubernetes 클러스터를 생성 하면 된다
ansible-playbook -i inventory/mycluster/hosts.yml --become --become-user=root cluster.yml이 한 명령어로 쿠버네티스 클러스터가 생성 된다 (네트워크 속도와 하드웨어 장비의 리소스의 따라 20 ~ 40 분 사이 시간 소요)
모든 설정들이 완료 되면 이런 화면이 보일 것이다
마스터 노드에서 확인
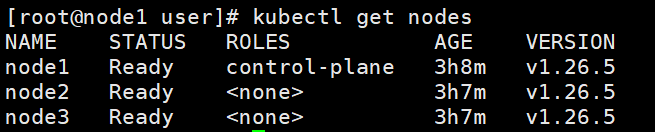
Worker노드들의 경우 기본적으로 특정 역할이 할당되지 않으므로 "<none>"으로 표시 된다. "Ready" 상태인 한, Worker 노드들은 올바르게 동작 한다.
추가로 <none> Label을 수동으로 바꿀 수 있는 명령어가 있다kubectl label node <노드 이름> node-role.kubernetes.io/worker=worker
변경 후:

웹 페이지 배포
쿠버네티스 클러스터는 이미 생성 되어 있는 관계로 바로 간단한 웹 페이지를 쿠버네티스 클러스터에 배포 및 테스트 해 보겠다.
제일 먼저 준비 해야 될 것은 물론 배포 해야 될 웹 페이지다. 일단 기존에 테스트 용으로 만든 장고 웹 사이트를 배포 해 보겠다.
먼저, 웹 애플리케이션을 K8s 클러스터에 배포하기 위해서는 애플리케이션의 컨테이너 이미지를 준비해야 한다. 일반적으로 Docker와 같은 컨테이너 플랫폼을 사용하여 애플리케이션을 컨테이너화 하고 이미지를 빌드 한다. 빌드 된 이미지는 컨테이너 레지스트리에 저장되어 클러스터 내에서 사용할 수 있게 된다.
웹 사이트의 소스 코드를 받은 후 Dockerfile을 추가 하였다. Dockerfile은 도커 이미지를 생성하기 위한 설정 파일이다. 이 파일에는 도커 이미지를 구성하는데 필요한 모든 단계와 명령어가 포함된다. Dockerfile을 작성하여 도커 이미지를 생성하면, 도커를 사용하여 해당 이미지를 기반으로 컨테이너를 실행할 수 있다.
# 파이썬 이미지 받기
FROM python:3.11
# 환경 변수 지정
ENV PYTHONUNBUFFERED 1
ENV PYTHONDONTWRITEBYTECODE 1
# 워킹 디렉터리 지정
WORKDIR /app
# 의존성 설치
COPY requirements.txt .
RUN pip install -r requirements.txt
# 컨테이너 안에 소스 코드 복사
COPY . .
# 장고 사이트가 실행 되기 위해 포트 열기
EXPOSE 8000
# 웹 사이트가 실행 하기 위해 초기 명령어
CMD ["python", "manage.py", "runserver", "0.0.0.0:8000"]마지막으로 이 Dockerfile을 빌드 및 Docker 레지스트리에 Push 해준다
# Dockerfile을 사용하여 커스텀 이미지 생성
docker build -t django:v2 ./
# 생성된 이미지 태그 달기
docker tag django:v1 waji97/django:v2
# 태그 된 이미지 레지스트리에 업로드
docker push waji97/django:v2이제 배포를 위해 매니페스트 YAML 파일을 작성 해야 된다. 파일 안에 먼저 Deployment 리소스를 사용하여 애플리케이션의 Replica을 지정 하고 어떤 이미지를 사용 하여 파드를 실행 시킬지 지정 한다. 그 후 Service 리소스 중 Nodeport 서비스를 사용하여 배포 된 웹 사이트를 접근 할 수 있게 포트 번호를 맞춰 준다.
# 매니페스트 파일 작성 및 적용을 위해 같은 경로 이동
mkdir myapp
cd myapp
# 매니페스트 파일 생성
vi my-app.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-app
spec:
replicas: 3
selector:
matchLabels:
app: my-app
template:
metadata:
labels:
app: my-app
spec:
containers:
- name: my-app
image: waji97/django:v2 # 방금 업로드한 웹 사이트 이미지
ports:
- containerPort: 8000
---
apiVersion: v1
kind: Service
metadata:
name: my-app-service
spec:
type: NodePort
selector:
app: my-app
ports:
- protocol: TCP
port: 80
targetPort: 8000
이렇게 YAML파일 지정 후 이 파일을 적용 시킨다
kubectl apply -f my-app.yaml
deployment.apps/my-app created
service/my-app-service created
적용 후 생성 되는 Pod, Deployment 그리고 Service를 확인 할 수 있다
# Pod 확인
kubectl get pods
NAME READY STATUS RESTARTS AGE
my-app-74dd96c584-9plfb 1/1 Running 0 30s
my-app-74dd96c584-lf97s 1/1 Running 0 30s
my-app-74dd96c584-tvl2n 1/1 Running 0 30s
# Service 확인
kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 18d
my-app-service NodePort 10.110.204.183 <none> 80:30001/TCP 50s
# Deployment 확인
kubectl get deployment
NAME READY UP-TO-DATE AVAILABLE AGE
my-app 3/3 3 3 40s
이제 결과를 확인 하기 위해 노드 중 아무 IP 주소에 30001 포트로 이동
웹 사이트 접속이 문제 없이 된다는 걸 확인 할 수 있다.
💡 만약에 웹 페이지를 수정 하거나, 새로운 웹 페이지의 이미지가 업로드 될 시, Deployment 리소스 덕분에 업데이트가 쉽게 가능하다. 웹 페이지를 배포한 매니페스트 파일 속에서 내가 원하는 이미지 이름을 수정 후 매니페스트 파일을 다시 적용 시키면 웹 사이트가 자동으로 새로운 이미지에 맞게 바뀐다.
간단한 테스트를 해 보았다
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-app
spec:
replicas: 3
selector:
matchLabels:
app: my-app
template:
metadata:
labels:
app: my-app
spec:
containers:
- name: my-app
#image: waji97/django:v2 # 기존 업로드한 웹 사이트 이미지
image: waji97/ecommerce:v2 # 새로 업로드한 웹 사이트 이미지
ports:
- containerPort: 8000
---
apiVersion: v1
kind: Service
metadata:
name: my-app-service
spec:
type: NodePort
selector:
app: my-app
ports:
- protocol: TCP
port: 80
targetPort: 8000
다시 업데이트 된 YAML파일을 적용 시킨다
kubectl apply -f my-app.yaml
deployment.apps/my-app configured
service/my-app-service unchanged
적용 후 웹 사이트 방문 결과
External ETCD (수정 중)
External etcd 구성은 쿠버네티스 클러스터에서 etcd 컴포넌트를 마스터 노드와 분리하여 외부에 배치하는 것을 의미한다.
etcd는 쿠버네티스 클러스터의 상태 정보를 안전하게 저장하기 위한 신뢰성 있는 분산형 키-값 저장소
이미 마스터 노드에 포함 되어 있는 컴포넌트를 따로 분리 하여 별도에 노드에 배치하여 제일 좋은 점은 보안이라고 볼 수 있다. 그 외에도 몇 가지 장점을 표현 한다면:
-
가용성 향상: etcd를 마스터 노드와 분리하여 외부에 배치하면 신뢰성과 가용성을 향상시킬 수 있다. 마스터 노드에 장애가 발생할 경우에도 etcd 클러스터가 별도로 유지되므로 클러스터의 상태 정보를 안전하게 유지할 수 있다.
-
확장성: 외부 etcd 클러스터를 사용하면 쿠버네티스 클러스터를 확장할 때 좀 더 유연성을 가질 수 있다. etcd 클러스터는 더 많은 리소스를 할당하여 고가용성 및 높은 처리량을 제공할 수 있으며, 대규모 클러스터 운영에 필수적이다.
-
유지 보수 및 업그레이드 용이성: etcd를 외부로 분리하면 클러스터의 유지 보수 및 업그레이드 작업이 간편해진다. 마스터 노드의 유지 보수 작업이 etcd 클러스터에 영향을 미치지 않고 수행될 수 있다.
-
분리된 관리 및 보안: etcd를 외부에 배치하면 마스터 노드에서 실행되는 다른 구성 요소와 분리된 관리와 보안을 제공할 수 있다. etcd 클러스터는 전용 네트워크 또는 보안 그룹을 통해 격리되어 안전한 환경에서 운영될 수 있다.
Etcd 컴포넌트를 마스터 노드에서 분리 하여 배치 하는 작업은 클러스터 생성시 설정을 하면 된다. 이미 Kubespray및 Kubeadm으로 클러스터를 생성 해 보았지만, etcd노드를 분리 하여 해 보지는 않았다. 그래서 이번에는 Kubespray를 통해 쿠버네티스 클러스터를 아래와 같은 구성으로 생성 해 보았다
- Control Node (Ubuntu 22.04): 192.168.1.90
- Master Node (CentOS 7): 192.168.1.150
- Worker Node (CentOS 7): 192.168.160
- ETCD Node (CentOS 7): 192.168.1.170
- ETCD Node 2 (CentOS 7): 192.168.1.180
- ETCD Node 3 (CentOS 7): 192.168.1.190
Kubespray를 통해 클러스터 생성
Kubespray를 통해 쿠버네티스 클러스터 생성 하는 방법은 이미 여기에 정리 해 놓았다. 설정 방법과 진행은 다 동일 하지만 다른 점은 hosts.yml 파일 속 추가 된 내용이다.
vi inventory/mycluster/hosts.yml
all:
hosts:
node1:
ansible_host: 192.168.1.150 # 작업을 실행하기 위해 대상 노드에 연결할 때 사용하는 IP 주소 또는 호스트 이름을 지정하는 필드
ip: 192.168.1.150
access_ip: 192.168.1.150
node2:
ansible_host: 192.168.1.160
ip: 192.168.1.160
access_ip: 192.168.1.160
node3:
ansible_host: 192.168.1.170
ip: 192.168.1.170
access_ip: 192.168.1.170
node4:
ansible_host: 192.168.1.180
ip: 192.168.1.180
access_ip: 192.168.1.180
node5:
ansible_host: 192.168.1.190
ip: 192.168.1.190
access_ip: 192.168.1.190
children:
kube_control_plane: # 마스터 노드 지정 하는 곳
hosts:
node1:
node2:
node3:
kube_node: # 워커 노드 지정 하는 곳
hosts:
node4:
etcd: # etcd 노드 지정 하는 곳
hosts:
node5:
k8s_cluster:
children:
kube_control_plane:
kube_node:
calico_rr:
hosts: {}이렇게 hosts.yml 파일 수정 후 Kubespray Ansible Playbook을 실행 한다. 아무 문제 없이 완료 되면 결과를 확인 할 수 있다.
이제 마스터 노드 쪽에서 클러스터 생성 결과를 확인 하기 위해:
it is normal that when you use the kubectl get nodes command from your master node, you will not see the etcd nodes included in the output. The kubectl get nodes command provides information about the worker nodes in your cluster, not the etcd nodes.
Etcd nodes are not considered as part of the worker node pool and are typically not included in the output of the kubectl get nodes command. Etcd operates as a separate distributed key-value store that stores the cluster's state and configuration information. It is responsible for providing data persistence and coordination among the control plane components.
Helm 패키지 매니저
Helm은 쿠버네티스 애플리케이션의 생성, 패키징, 구성 및 배포를 자동화하는 도구이다. 구성 파일을 하나로 결합하여 재 사용 가능한 패키지로 만들어 준다.
Microservice 아키텍처에서 애플리케이션이 커짐에 따라 더 많은 microservice를 생성하는 경우 관리가 점점 어려워 진다. 쿠버네티스는 오픈 소스 컨테이너 오케스트레이션 기술로, 여러 microservice를 하나의 배포로 그룹화하여 프로세스를 단순화 한다. 그러나 개발 수명 주기 동안의 쿠버네티스 애플리케이션 관리는 버전 관리, 리소스 할당, 업데이트 및 롤 백과 같은 도전 과제를 동반 한다.
Helm은 이러한 문제에 대한 가장 접근 가능한 해결책 중 하나를 제공하여 배포를 더 일관적이고 반복 가능하며 신뢰할 수 있게 만들어 주었다.
쿠버네티스 관리의 단순화를 위한 Helm 컨테이너는 애플리케이션과 해당 종속성을 단일 이미지 파일로 묶는 경량 소프트웨어 구성 요소이다. 컨테이너는 다양한 플랫폼 간에 이식할 수 있으므로 애플리케이션 시작 시간이 빨라지고 쉬운 확장이 가능 하다.
쿠버네티스는 YAML 구성 파일을 사용하여 배포한다. 그렇기 때문에 자주 업데이트되는 복잡한 배포의 경우 이러한 파일의 다양한 버전을 추적하는 것은 어려울 수 있다. Helm은 단일 배포 YAML 파일에 버전 정보를 유지하는 편리한 도구이다. Helm은 Helm 차트 라는 쿠버네티스 클러스터에 애플리케이션을 배포하기 위해 필요한 모든 리소스를 포함하는 패키지 파일이다. 배포, 서비스, Secrets 및 ConfigMap에 대한 YAML 구성 파일을 포함하여 애플리케이션의 원하는 상태를 정의한다.
Helm 차트는 YAML 파일과 템플릿을 함께 패키징하여 매개 변수화된 값을 기반으로 추가 구성 파일을 생성할 수 있다. 이를 통해 환경에 맞게 구성 파일을 사용자 정의하고 다양한 배포에 재사용 가능한 구성을 만들 수 있다. 또한 각 Helm 차트는 독립적으로 버전 관리되므로 다른 구성을 가진 애플리케이션의 여러 버전을 쉽게 유지할 수 있다.
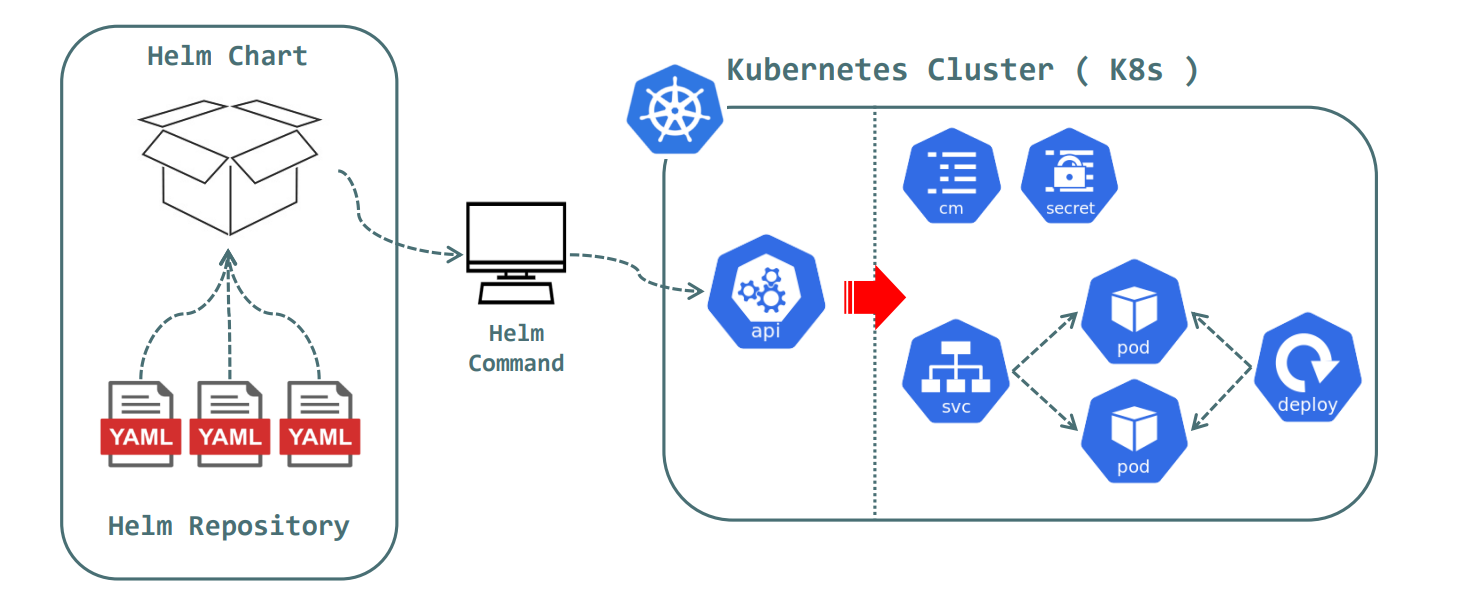
Helm 아키텍처는 버전 2와 3 사이에서 크게 개선되었다. 버전 2는 Tiller 서버를 사용하여 Helm 클라이언트와 Kubernetes API 서버 간의 중개를 담당했다. Helm을 클러스터에 설치할 때 Tiller가 필요하며 보안 이슈가 있을 수 있습니다. 그러나 Helm 3에서는 Tiller가 제거되었고 Helm 클라이언트가 직접 Kubernetes API 서버와 상호 작용하도록 변경되었습니다.
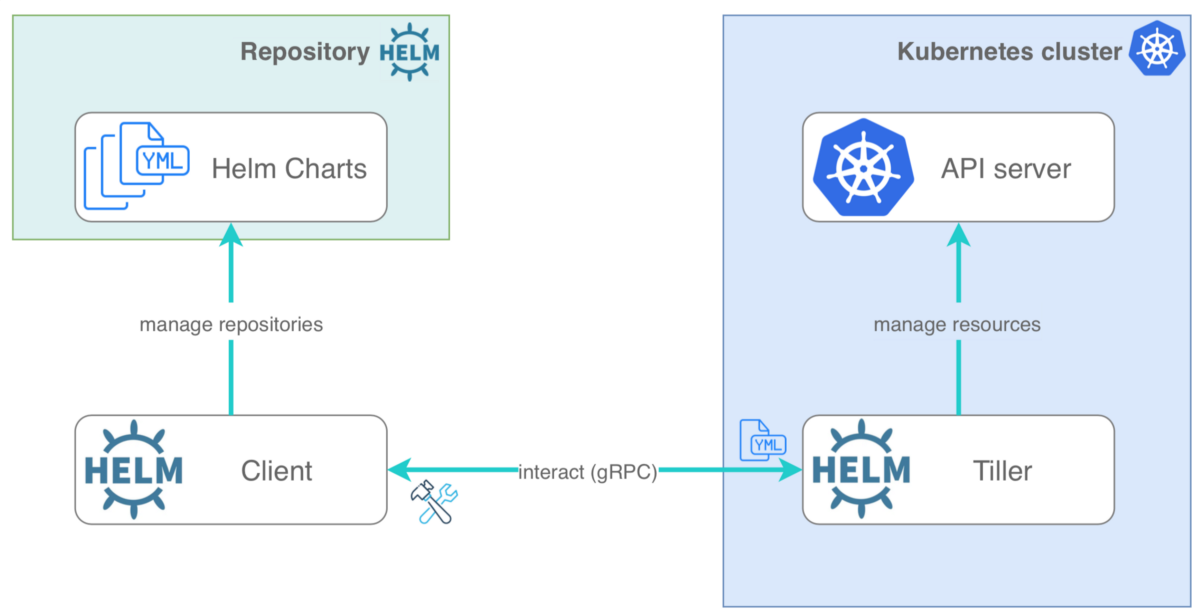
Version 3
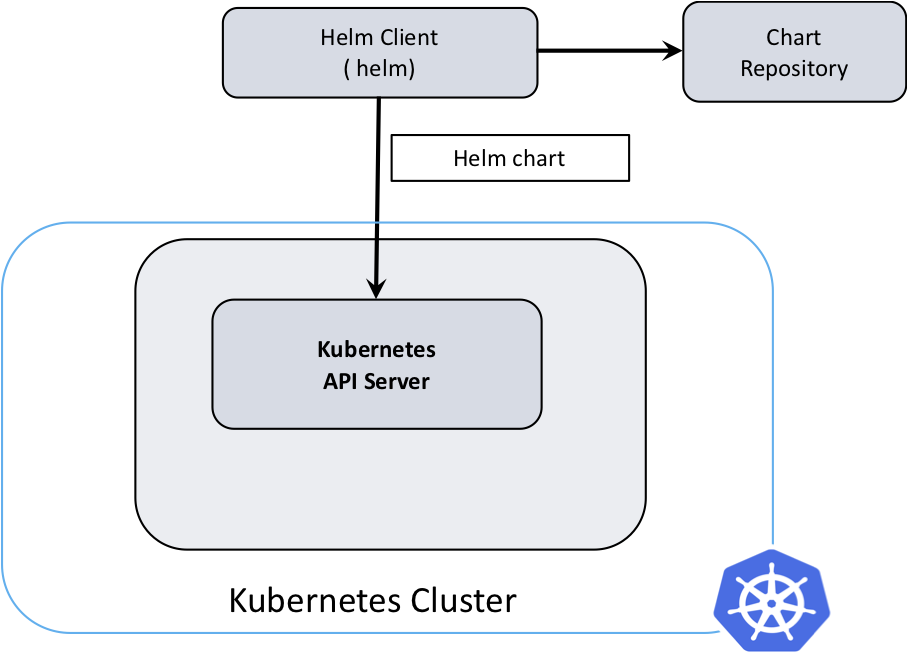
요약하자면, Helm은 쿠버네티스 애플리케이션 관리를 단순화하는 도구입니다. Helm 차트를 사용하여 애플리케이션의 배포, 구성 및 관리를 쉽게 할 수 있습니다. Helm은 YAML 파일로 구성된 리소스를 패키지로 묶어 재사용 가능한 차트를 생성하며, Helm 클라이언트와 라이브러리를 통해 쿠버네티스 클러스터와 상호 작용합니다.
Helm 설치
Helm 설치하기 전, Git 먼저 설치
# Red Hat 계열
dnf install git
# 우분투 계열
sudo apt install gitHelm 설치 하는 방법은 간단하다. 설치 방법들은 공식 Installation 페이지에서 확인 가능.
많은 설치 방법들 중에 스크립트로 설치하는 방법으로 진행 하였다
# 설치 스크립트를 가져온 다음 로컬에서 실행 한다
curl -fsSL -o get_helm.sh https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3
# 스크립트 실행하기 위해 권한 수정
chmod 700 get_helm.sh
# 스크립트 실행
./get_helm.sh
Downloading https://get.helm.sh/helm-v3.12.0-linux-amd64.tar.gz
Verifying checksum... Done.
Preparing to install helm into /usr/local/bin
helm installed into /usr/local/bin/helm
# 버전 확인
helm version
version.BuildInfo{Version:"v3.12.0", GitCommit:"c9f554d75773799f72ceef38c51210f1842a1dea", GitTreeState:"clean", GoVersion:"go1.20.3"}배포 전략 및 설정
배포 전략
쿠버네티스에서 애플리케이션을 배포할 때, 다양한 배포 전략을 고려하는 것이 중요하다. 이를 통해 어플리케이션의 안정성, 확장성, 사용자 경험 등을 최적화할 수 있다. 아래에서 가장 일반적으로 사용되는 배포 전략 몇 가지를 살펴보겠다.
1. 롤링 업데이트 (Rolling Update)
롤링 업데이트는 새로운 버전의 애플리케이션을 점진적으로 배포하는 전략이다. 이전 버전의 파드들을 점차적으로 새로운 버전으로 교체하면서 서비스의 가용성을 유지 한다. 롤링 업데이트는 다음과 같은 단계로 진행된다.
- 새로운 버전의 파드를 클러스터에 추가한다.
- 서비스의 로드밸런서를 통해 새로운 파드들에 트래픽을 점진적으로 라우팅 한다.
- 이전 버전의 파드들을 하나씩 제거하면서 새로운 버전의 파드로 교체 한다.
롤링 업데이트는 배포 과정 중에 중단 없이 서비스를 계속 제공할 수 있으며, 문제가 발생한 경우 롤백도 쉽게 수행할 수 있다.
2. 블루-그린 배포 (Blue-Green Deployment)
블루-그린 배포는 새로운 버전의 애플리케이션을 기존 버전과 완전히 분리된 환경에서 배포하고, 완전히 검증된 후에 트래픽을 전환하는 전략이다. 다음은 블루-그린 배포의 단계다:
- 블루 환경에 현재 운영 중인 애플리케이션 버전을 배포한다.
- 그린 환경에 새로운 버전의 애플리케이션을 배포하고 테스트 한다.
- 테스트가 성공적으로 완료되면 로드밸런서를 이용하여 트래픽을 블루에서 그린으로 전환 한다.
- 그린 환경에서 정상적으로 동작하는지 확인한 후, 필요에 따라 블루 환경을 제거 한다.
블루-그린 배포는 롤백 시에도 용이하며, 사용자에게 거의 무감각한 배포를 제공할 수 있다. 하지만 추가 인프라 자원이 필요하며, 배포 시간도 더 오래 걸릴 수 있다.
3. 카나리아 배포 (Canary Deployment)
카나리아 배포는 새로운 버전의 애플리케이션을 일부 사용자 또는 트래픽의 일부에게 노출시켜서 테스트하고, 성능 및 안정성을 확인한 후에 전체로 확장하는 전략 이다. 아래는 카나리아 배포의 주요 단계들이다:
- 새로운 버전의 애플리케이션을 일부 파드로 배포 한다.
- 로드밸런서를 통해 일부 사용자 또는 일부 트래픽을 새로운 버전의 파드로 라우팅 한다.
- 새로운 버전의 파드들에서 성능 및 안정성을 모니터링하고 평가 한다.
- 테스트가 성공적으로 완료되면 나머지 파드들에 새로운 버전을 배포하고, 모든 트래픽을 새로운 버전으로 전환 한다.
카나리아 배포는 배포 전략의 일부분을 선택적으로 테스트할 수 있는 유연성을 제공하며, 더 많은 피드백과 데이터를 수집할 수 있다. 그러나 추가적인 관리 비용이 발생하며, 배포 프로세스가 복잡해질 수 있다.
배포 설정
쿠버네티스 에서 애플리케이션을 배포하기 위해서는 몇 가지 기본 설정이 필요하다. 아래는 일반적으로 사용되는 배포 설정의 예시들이다.
1. Pod 정의
애플리케이션의 실행을 담당하는 파드를 정의해야 한다. 이를 위해 Pod의 설정 파일을 작성하고, 컨테이너 이미지, 리소스 요구사항, 환경 변수, 포트 포워딩 등을 설정해야 한다.
2. 서비스 정의
애플리케이션에 접근하기 위한 서비스를 정의해야 한다. 서비스는 파드 집합에 대한 로드밸런싱을 처리하고, 네트워크 연결을 제공한다. 클러스터 내부 또는 외부에서 접근 가능한 엔드포인트를 설정할 수 있다.
3. 볼륨 및 볼륨 클레임 정의
애플리케이션에서 사용하는 데이터를 보존하기 위해 볼륨과 볼륨 클레임을 정의해야 한다. 이를 통해 데이터의 지속성과 공유를 보장할 수 있다.
4. 배포 및 스케일링 설정
애플리케이션의 배포 전략을 선택하고 설정해야 한다. 롤링 업데이트, 블루-그린 배포, 카나리아 배포 등의 전략을 적용할 수 있으며, 파드 의 수를 조정하여 스케일링할 수도 있다.
5. 모니터링 및 로깅 설정
애플리케이션의 모니터링과 로깅 을 위한 설정을 추가해야 한다. 이를 통해 애플리케이션의 상태를 추적하고, 문제를 진단하고 해결할 수 있다. 예를 들어 Prometheus, Grafana, ELK 스택 등의 도구를 활용할 수 있다.
6. 보안 설정
애플리케이션에 대한 보안 설정을 추가해야 한다. 인증, 권한 부여, 네트워크 정책 등을 구성하여 애플리케이션의 안전성을 강화할 수 있다.
이는 일반적인 설정 예시일 뿐이며, 실제 애플리케이션의 요구 사항에 따라 설정이 달라질 수 있다
노드 관리
쿠버네티스에서 노드는 클러스터의 실행 환경으로서 컨테이너화된 애플리케이션을 실행하는 물리적인 또는 가상의 서버이다. 노드 관리는 클러스터의 성능, 안정성 및 가용성을 유지하는 데 중요한 역할을 한다.
1. 노드 추가 및 제거
쿠버네티스에서는 클러스터에 노드를 추가하거나 제거할 수 있다. 새로운 노드를 추가하면 클러스터의 자원 용량이 증가하고 애플리케이션의 수평 확장이 가능해진다. 노드를 제거할 때는 해당 노드에서 실행 중인 파드를 안전하게 이동시키고 클러스터의 자원 사용을 최적화해야 한다.
2. 노드 상태 모니터링
쿠버네티스는 노드의 상태를 지속적으로 모니터링하여 노드의 가용성을 확인 한다. 노드가 정상 상태인지 여부를 확인하고, 필요한 경우 노드의 비정상적인 동작을 감지하고 조치 한다. 이를 통해 클러스터는 노드 장애에 대응하고 애플리케이션의 지속적인 가용성을 유지할 수 있다.
3. 노드 레이블링
쿠버네티스에서는 노드에 레이블을 지정하여 특정 속성이나 기능을 가진 노드를 식별할 수 있다. 노드 레이블은 노드 선택, 파드 스케줄링, 네트워크 정책 등과 같은 다양한 용도로 활용될 수 있다. 이를 통해 애플리케이션을 특정 노드에 배치하거나 특정 노드에서 실행되는 파드 간의 통신을 제어할 수 있다.
4. 노드 업그레이드
쿠버네티스에서는 노드의 운영체제, 컨테이너 런타임, 커널 등을 업그레이드할 수 있다. 노드 업그레이드는 애플리케이션의 가용성을 유지하기 위해 롤링 업데이트 전략을 사용하여 점진적으로 업그레이드를 수행 한다. 이를 통해 클러스터의 노드를 최신 버전으로 유지하고 보안 패치를 적용할 수 있다.
//Cron과 Drain?
https://arisu1000.tistory.com/27845
리소스 관리
- 라벨링과 애노테이션
모니터링과 로깅
- 메트릭 수집
- 로그 관리
스케일링 및 롤링 업데이트
쿠버네티스는 애플리케이션의 수평 스케일링과 롤링 업데이트를 지원하여 애플리케이션의 성능 향상과 지속적인 개선을 가능하게 한다. 이를 통해 애플리케이션을 더욱 확장 가능하고 안정적으로 운영할 수 있다.
1. 수평 스케일링
쿠버네티스는 파드의 수를 동적으로 조정하여 애플리케이션의 수평 스케일링을 지원 한다. 파드 수를 늘리면 애플리케이션의 처리량과 부하 분산이 증가하며, 반대로 파드 수를 줄이면 자원 사용량을 최적화할 수 있다. 이를 통해 애플리케이션의 성능을 향상시킬 수 있다.
2. 롤링 업데이트
롤링 업데이트는 애플리케이션의 새 버전을 점진적으로 배포하는 과정을 말한다. Kubernetes는 롤링 업데이트를 통해 애플리케이션의 가용성을 유지하면서 새로운 버전으로의 전환을 원활하게 처리한다. 롤링 업데이트는 애플리케이션의 가용성을 유지하면서 시스템의 안정성을 보장한다.
3. 블루-그린 배포
블루-그린 배포는 새로운 버전의 애플리케이션을 별도의 환경에 배포한 후, 기존 버전과 새 버전 사이에서 전환하는 전략이다. 쿠버네티스는 블루-그린 배포를 지원하며, 서비스의 라우팅 설정을 변경하여 전환을 수행한다. 이를 통해 애플리케이션의 변경 사항을 테스트하고 문제가 발생하지 않으면 전환을 완료할 수 있다.
클러스터 업그레이드
kubectl 자동 완성 (수정 중)
쿠버네티스의 자동 완성 기능은 긴 쿠버네티스 리소스 이름을 자동 완성 시킬때 꽤 유용 하다.
자세한 정보는
먼저
type _init_completion
명령어를 사용하여 이미 설정이 되어 있는지 부터 확인
안되어 있는 경우:
type _init_completion
-bash: type: _init_completion: not found
설정 하려면:
만약에 위 명령어 사용 시 'Not Found' 애러 발생 하면, 먼저 'bash-completion'툴을 설치 하고 다시 진행 해야 한다
RHEL 계열:
dnf install bash-completion
Ubuntu 계열:
apt install bash-completion
설정 후
type _init_completion
_init_completion is a function
_init_completion ()
{
local exclude= flag outx errx inx OPTIND=1;
while getopts "n:e:o:i:s" flag "$@"; do
case $flag in
n)
exclude+=$OPTARG
;;
e)
errx=$OPTARG
;;
o)
outx=$OPTARG
;;
i)
inx=$OPTARG
;;
s)
split=false;
exclude+==
;;
esac;
done;
COMPREPLY=();
local redir="@(?([0-9])<|?([0-9&])>?(>)|>&)";
_get_comp_words_by_ref -n "$exclude<>&" cur prev words cword;
_variables && return 1;
if [[ $cur == $redir* || $prev == $redir ]]; then
local xspec;
case $cur in
2'>'*)
xspec=$errx
;;
*'>'*)
xspec=$outx
;;
*'<'*)
xspec=$inx
;;
*)
case $prev in
2'>'*)
xspec=$errx
;;
*'>'*)
xspec=$outx
;;
*'<'*)
xspec=$inx
;;
esac
;;
esac;
cur="${cur##$redir}";
_filedir $xspec;
return 1;
fi;
local i skip;
for ((i=1; i < ${#words[@]}; 1))
do
if [[ ${words[i]} == $redir* ]]; then
[[ ${words[i]} == $redir ]] && skip=2 || skip=1;
words=("${words[@]:0:i}" "${words[@]:i+skip}");
[[ $i -le $cword ]] && cword=$(( cword - skip ));
else
i=$(( ++i ));
fi;
done;
[[ $cword -eq 0 ]] && return 1;
prev=${words[cword-1]};
[[ -n ${split-} ]] && _split_longopt && split=true;
return 0
}
그 후 쿠버네티스 상 자동 완성 설정. 이제 kubectl 자동 완성 스크립트가 모든 셸 세션에서 제공되도록 해야 한다. 이를 수행할 수 있는 두 가지 방법이 있다.
현재 사용자에게 만 설정
echo 'source <(kubectl completion bash)' >>~/.bashrc
모든 사용자에게 설정
ubectl completion bash | sudo tee /etc/bash_completion.d/kubectl > /dev/null
[root@node1 ~]# exec bash
[root@node1 ~]# kubectl get ns
default kube-node-lease kube-public kube-system
[root@node1 ~]# kubectl get ns
// 미완성
Bastion에서 Kubectl 쓰기 (수정 중)
References:
Installting Kubectl: https://kubernetes.io/docs/tasks/tools/
curl -LO https://dl.k8s.io/release/v1.24.6/bin/linux/amd64/kubectl
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 138 100 138 0 0 666 0 --:--:-- --:--:-- --:--:-- 666
100 43.6M 100 43.6M 0 0 21.0M 0 0:00:02 0:00:02 --:--:-- 29.6M
ls
kubectl kubespray kubesprayv2.20 original-ks.cfg
curl -LO https://dl.k8s.io/release/v1.24.6/bin/linux/amd64/kubectl.sha256
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 138 100 138 0 0 650 0 --:--:-- --:--:-- --:--:-- 650
100 64 100 64 0 0 122 0 --:--:-- --:--:-- --:--:-- 122
ls
kubectl kubectl.sha256 kubespray kubesprayv2.20 original-ks.cfg
echo "$(cat kubectl.sha256) kubectl" | sha256sum --check
kubectl: OK
sudo install -o root -g root -m 0755 kubectl /usr/local/bin/kubectl
kubectl version --client
WARNING: This version information is deprecated and will be replaced with the output from kubectl version --short. Use --output=yaml|json to get the full version.
Client Version: version.Info{Major:"1", Minor:"24", GitVersion:"v1.24.6", GitCommit:"b39bf148cd654599a52e867485c02c4f9d28b312", GitTreeState:"clean", BuildDate:"2022-09-21T13:19:24Z", GoVersion:"go1.18.6", Compiler:"gc", Platform:"linux/amd64"}
Kustomize Version: v4.5.4
# Master노드에 있는 '.kube/config' 파일을 복붙
mkdir .kube
cd .kube
vi config
# 그대로 복붙 하면 안됨, 왜냐면 거기에서는 로컬 호스트로 지정 되어 있음
kubectl get nodes
The connection to the server 127.0.0.1:6443 was refused - did you specify the right host or port?
# 그래서 5번째 줄에서 서버 IP를 Master노드 IP로 지정
vi config
server: https://192.168.122.8:6443
kubectl get nodes
NAME STATUS ROLES AGE VERSION
node1 Ready control-plane 13d v1.24.6
node2 Ready <none> 13d v1.24.6
node3 Ready <none> 13d v1.24.6